2024. 1. 21. 22:45ㆍTools & Skills/Python
파이썬의 대표적인 시각화 도구에는 matplotlib와 seaborn이 있다.
seaborn은 matplotlib 대비 쉽게 그래프를 그리고 그래프 스타일을 설정할 수 있다는 장점이 있으며,
정교하게 그래프의 크기를 조절하거나 각 축의 범례값을 조절할 때에는 matplotlib을 함께 사용하기도 한다.
그러나, seaborn 사용법에 익숙해진다면 큰 문제가 되지 않으므로 많이 연습해보자
필요한 패키지를 임포트
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
df = pd.read_csv('mpg.csv')
df
그래프 4개 그리기
import matplotlib.gridspec as gridspec # 여러 Axes 배치
gird = gridspec.GridSpec(2,2) # 4가지 그래프를 그리려고 함
plt.figure(figsize=(16,10))
plt.subplots_adjust(wspace=0.5, hspace=0.4) # 그래프가 여러 개 그려질 경우 충돌 방지
mpg_features = ['manufacturer', 'model', 'category', 'drv'] # 범주형 데이터 가지고 그래프 그리기 문자열 데이터들
# sns countplot 그리기
fot idx, featrue in enumerate(mpg_featrues): # 순서가 있는 자료형을 입력 받아 각 원소를 인덱스와 값의 쌍으로 반환
ax = plt.subplot(gird[idx])
# sns countplot 파라미터들
sns.countplot(x = feature,
data = df,
hue = 'drv', # 막대 내의 추가적인 범주 분류
palette = 'pastel', # 범주형 색상 지정
ax = ax) # 그래프를 그릴 Matplotlib의 subplot
plt.xticks(rotation=90) # x축의 값을 축전환하는 코드
ax.set_title(f'{feature} Distribution')
다양한 Seaborn 시각화 그래프들
sns.histplot
sns.histplot 은 Seaborn에서 히스토그램을 그리기 위한 함수이다.
히스토그램은 숫자형 데이터를 그룹(bin)으로 집약하고 각 bin에 속해 있는 값의 빈도를 표시한다.
히스토그램은 "숫자 값의 분포와 데이터셋에 숫자 값이 나타나는 빈도는?", "이상치 유무는?" 등의 데이터 관련 질문에 답변하기 적합하다.
sns.histplot(df['age', bins = 20, kde = True) # kde : 연속확률분포 그래프 그리기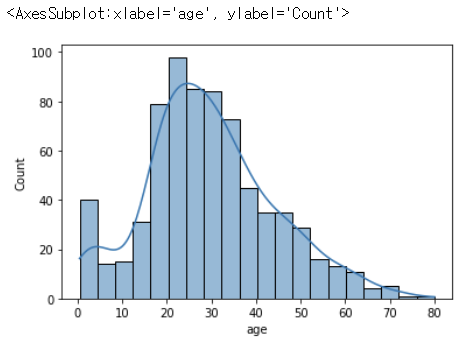
sns.count()
sns.count()를 이용하면 데이터프레임에서 원하는 열의 각각의 고유한 값의 개수를 세어 그래프에 표현할 수 있다.
# count를 x축과 y축을 지정할 수 있고
sns.barplot(x='pclass', y='survived', data=df)
sns.barplot()
sns.barplot(x='pclass', y='sex', data=df)
# y축이 범주형 변수로 들어가게 되면 반전 되면서 아래 그래프처럼 보이게 된다.
hue 인자를 넣으면 범례를 추가하게 되는 것!
sns.barplot(x='pclass', y='survived', hue='sex', data=df)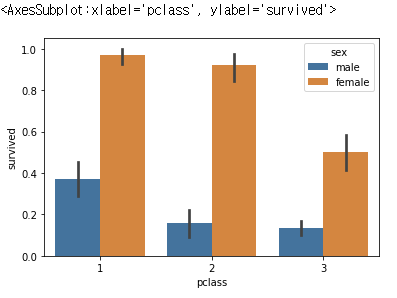
sns.boxplot()

주식, 코인 등에서 볼 수 있는 캔들이라고 부르는 차트 유형인데 박스플롯 차트를 응용한 유형이다.
박스플롯은 데이터의 분포와 이상치를 동시에 보여주면서
서로 다른 데이터군을 쉽게 비교할 수 있는 데이터 시각화 유형이다.
예제 코드로 살펴보자
sns.boxplot(x='pclass', y='age', hue = 'survived',data=df)
sns.violinplot()
바이올린차트는 박스 플롯과 동일하게 일변량, 연속형 데이터의 분포를 설명하기 위해 사용되는 그래프이다.
대부분의 내용이 박스 플롯과 같으며, 카테고리값에 따른 각 분포의 실제 데이터 또는 전체 형상을 보여준다는 장점 존재!
sns.violinplot(x='pclass', y='age', hue='survived', data=df)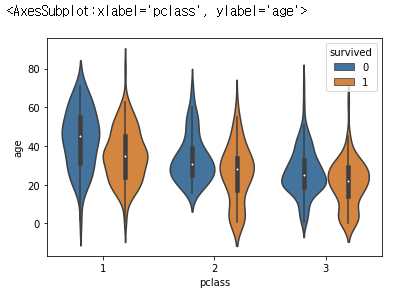
앞서 다양한 시각화들은 시각화하고자 하는 내용을 반복문으로 간편하게 한 번에 처리할 수 있다.
다만, 반복문으로 접근할 때 countplot는 수를 세는 것 y축이 고정되어 있지만,
barplot는 자유롭게 y축과 estimator를 조절할 수 있음을 기억하자
# countplot
tt_columns = ['embarked', 'pclass', 'sex']
fig, axs = plt.subplots(nrows=1, ncols= len(tt_columns), figsize=(15,3))
for idx, columns in enumerate(tt_columns):
print('idx', idx)
sns.countplot(x=columns, data=df, ax=axs[idx])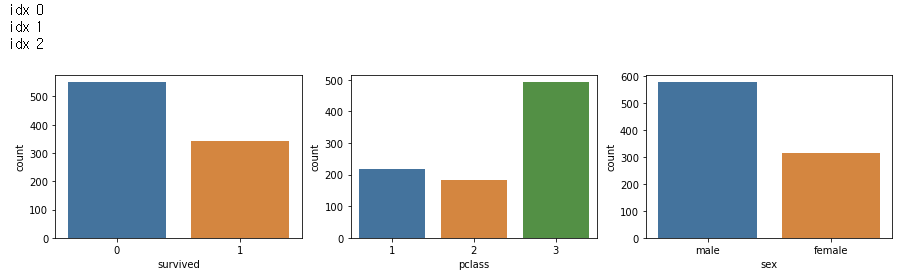
# barplot()
tt_columns = ['embarked', 'pclass', 'sex']
fig, axs = plt.subplots(nrows=1, ncols=len(tt_columns), figsize=(15,3))
for idx, columns in enumerate(tt_columns):
print('idx', idx)
sns.barplot(x=columns, y='survived', data=df, ax=axs[idx], estimator=sum)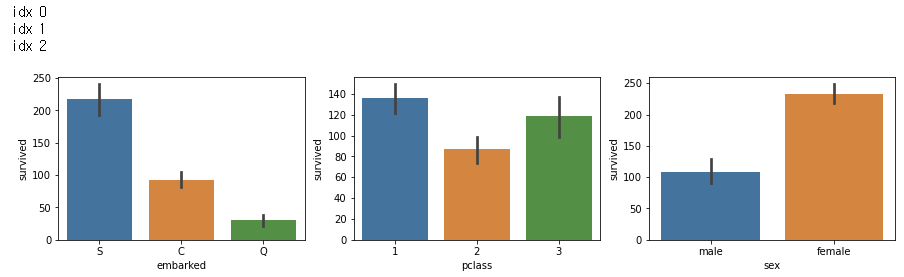
시계열 데이터
시계열 데이터(Time-series data)는 주식 가격, 기상 정보, 웹사이트의 사용자 트래픽 등
시간 순서에 따라 관측된 데이터를 의미한다.

시계열 데이터의 종류에는 시간에 따른 패턴이나 추세를 보이는 시계열 데이터와 그렇지 않은 데이터가 있다.
패턴을 보이는 데이터는 일년 중 특정 기간에만 나타는 패턴 등을 보이며,
패턴이 없는 데이터는 일정한 추세가 없거나 불규칙한 데이터이다.
시계열 데이터 분석
시계열 데이터는 기존의 분석과는 다르다.
보간법에서 확인한 것처럼, 시간의 흐름에 따라 데이터가 특성이 생성된다.
그러나, 이 시간의 흐름을 임의로 변경한다면 시간의 특성이 사라져 예측을 진행할 때 문제가 될 수 있다.
따라서 ML에서는 train_test_split를 사용하여 time과 관련해 데이터를 분할한다.
시간 독립 모델 vs 시간 종속 모델
시간 독립 모델 : 과거의 데이터가 미래의 데이터에 영향을 미치지 않는다고 가정
시간 종속 모델 : 과거의 데이터가 미래의 데이터에 영향을 준다고 가정
먼저, 파이썬에서 날짜와 시간을 다루는 라이브러리 중 하나인 datetime을 이용하여 시계열 데이터를 다뤄보자
import pandas as pd
import datetime
# datetime으로 시계열 데이터 만들기
date = datetime.date(year=2023, month=11, day=26)
time=datetime.time(hour=23, minute=29, second=5, microsecond=1234)
dt = datetime.datetime(year=2023, month=11, day=26, hour=23, minute=29, second=5, microsecond=1234)
# timedelta : 객체를 가지고 있으면서 시간의 계산 가능
td = datetime.timedelta(days=31)
print(date)
print(time)
print(dt)
print(td)
datetime.date(2023, 11, 26) # date
datetime.time(23, 29, 5, 1234) # time
datetime.datetime(2023, 11, 26, 23, 29, 5, 1234) # dt
datetime.timedelta(days=31) # td
pd.to_datetime(날짜)
datetime 판다스에서 제공하는 아주 편한 메서드 중
다양한 날짜 표기법을 자동으로 시계열 데이터로 인식해주는 함수이다.
# pd.to_datetime의 좋은 예시
eg_dt = pd.Series(['2023-11-26','2023/11/26','2023.11.26','26-11-2023','26/11/2023','2023-13-26','2023-11-32'])
0 2023-11-26
1 2023-11-26
2 2023-11-26
3 2023-11-26
4 2023-11-26
5 NaT
6 NaT
dtype: datetime64[ns]
이제 실제 데이터를 가지고 시계열 데이터를 만들어 보자
# 파일 불러오기
df = pd.read_csv('crime.csv')
print(df)
print(df.info()
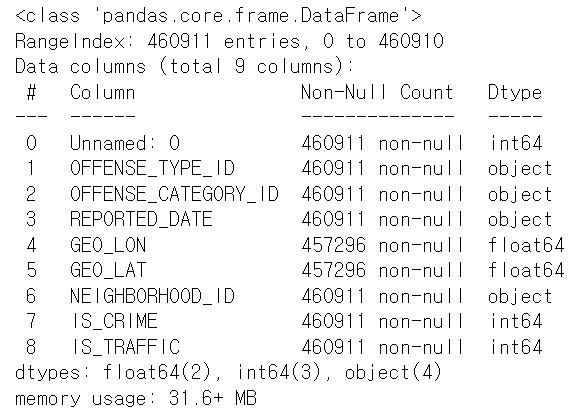
시계열 데이터를 다룰 때는 가장 먼저 시계열 데이터를 시계열 데이터 타입으로 만들어야 한다.
# datetime으로 변환
df['REPORTED_DATE'] = pd.to_datetime(df['REPORTED_DATE'])
print(df.info())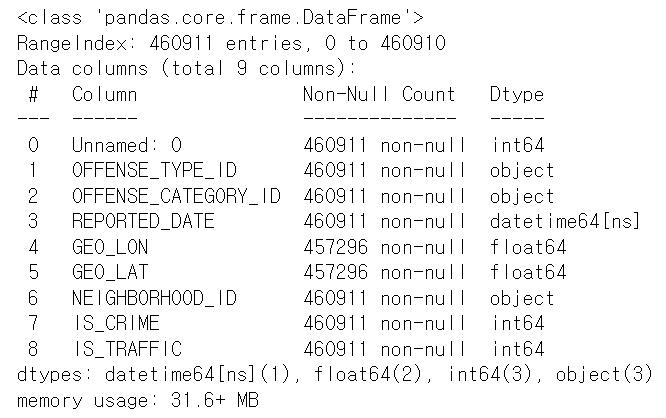
다음으로 시계열 데이터를 쉽게 가공하기 위해서는 index를 지정해야 한다.
df = df.set_index('REPORTED_DATE')
print(df)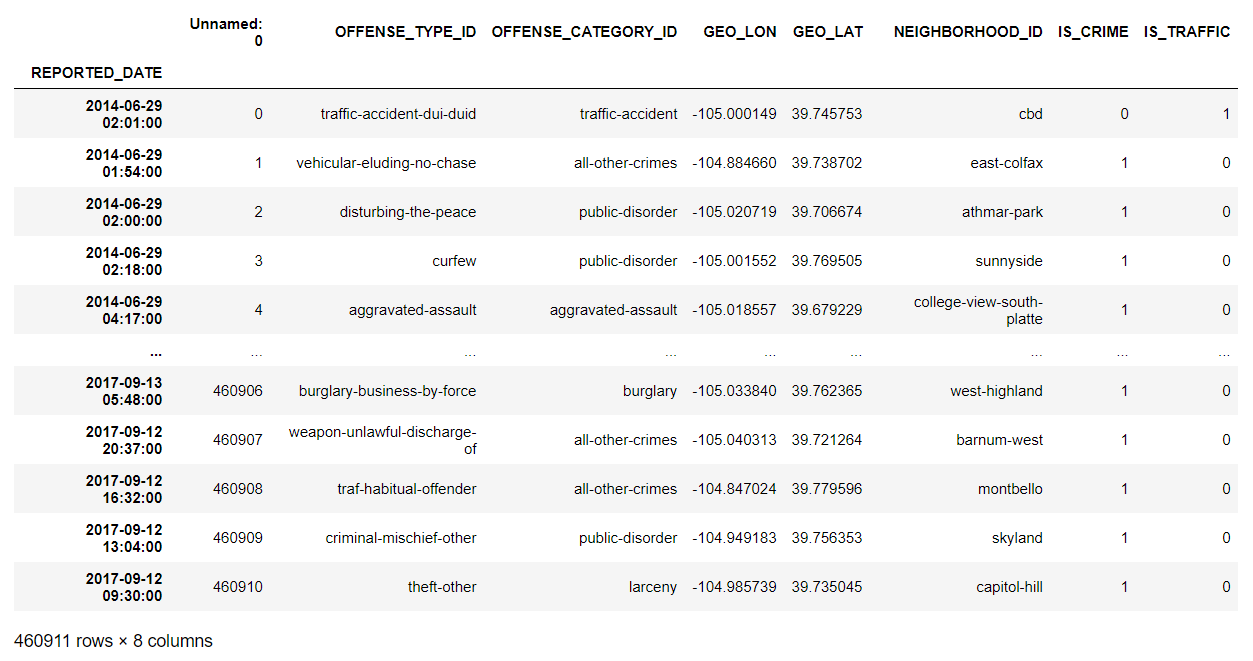
index를 지정했다면 자유롭게 시계열 데이터를 가지고 놀 수 있다.
df.ioc['2017'] # 2017년도에 해당하는 데이터만 추출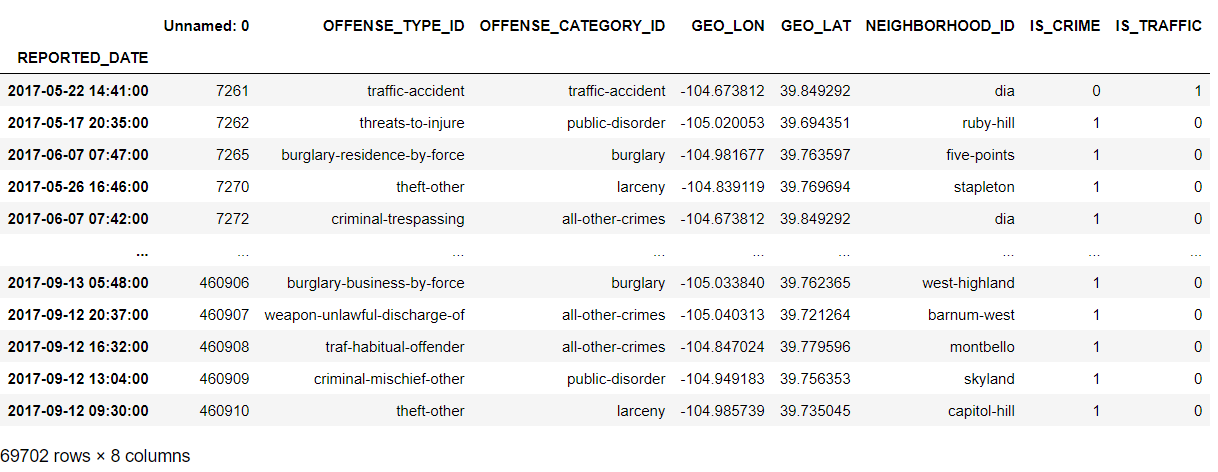
정각 시간에도 데이터 추출이 가능하다
df.at_time('14:00')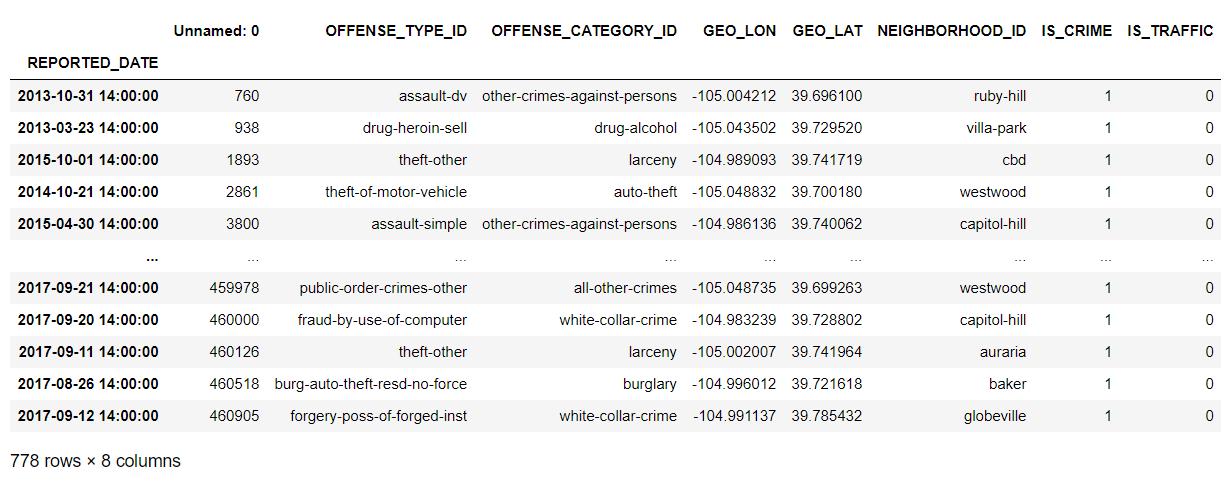
시계열 문법 중 특정 기준의 날짜들을 추출할 수 있도록 도와주는 메서드가 있다.
offsets : 시간 주기를 나타내기 위한 다양한 옵션을 제공하는 모듈
resample : Datetime index를 원하는 주기로 나눠주는 메서드 (Y,M,W,D, ...)
df.resample('Y').sum() # 주기 연도별로 재샘플링하고, 각 연도에 대한 합 계산
이를 이용하면 해당 사건에 대한 전체 합을 계산할 수 있다.
df_crime = df[['is_crime']]
df_crime.resample('Y').sum()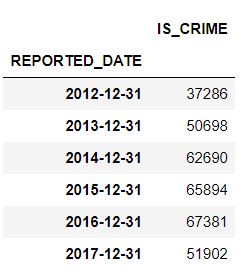
참고
16-08 리샘플링 (resample)
####DataFrame.resample(rule, axis=0, closed=None, label=None, convention='start', kind=None, loffse…
wikidocs.net
'Tools & Skills > Python' 카테고리의 다른 글
| 데이터 병합 (1) | 2024.01.15 |
|---|---|
| 데이터 전처리 문법 중급 (0) | 2024.01.12 |
| Outlier! (0) | 2024.01.12 |
| 결측치와 누락값 (2) | 2024.01.07 |
| 데이터 전처리 기본기 (0) | 2024.01.02 |