2024. 1. 15. 16:13ㆍTools & Skills/Python
데이터 병합
데이터 병합은 DE, DA, DS 등 데이터를 다루는 직군이라면 필수적으로 알아야 하는 개념이다.
SQL 쪽에서는 기본적으로 join을 이용하여 테이블 query를 추출하는데,
데이터베이스 시스템에서 내부적으로 최적화되어 많은 데이터를 효율적으로 처리 가능!
반면, python은 범용 프로그래밍 언어이기 때문에 데이터 처리에 특화된 최적화가 내장되어 있지 않다.
이는 대용량 데이터를 다루거나 복잡한 데이터 조작이 필요한 경우 성능 이슈가 발생할 수 있는 것!
1. Concat()
이전 포스팅에서 간단히 다룬 concat() 함수는 데이터프레임끼리 합쳐지는 것이다.
그렇기 때문에 따로 어떤 join 조건은 없다.
concat 함수의 매개변수에는 axis 와 ignore_index 가 있다.
# axis : 데이터프레임을 이어붙이는 방향을 지정하는 것
✅ axis = 0 : 수직 방향, 위아래로 이어붙임
✅ axis = 1 : 수평 방향, 좌우로 이어붙임
# ignore_index : 병합된 결과에 대한 인덱스 재설정 여부
✅ ignore_index = True : 새로운 연속적인 정수로 인덱스 재설정
✅ ignore_index = False : 각각의 데이터프레임의 인덱스 유지
코드 예제를 통해 알아보자
import pandas as pd
df1 = pd.DataFrame({'A':[1,2,3], 'B':[4,5,6]})
df2 = pd.DataFrame({'A':[4,5], 'B':[6,7]})
df3 = pd.DataFrame({'A':[7,8,9], 'B':[10,11,12], 'C':[13,14,15]})
display(df1)
display(df2)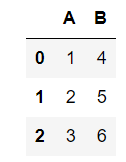

display(pd.concat([df1,df2], axis=0)) # 0행, 1열 기준
display(pd.concat([df1,df2], axis=1)) # 0행, 1열 기준
display(pd.concat([df2,df1], axis=0, ignore_index=True)) # 인덱스를 새롭게 정렬


concat 함수는 시계열 인덱스 날짜 기준으로 데이터를 붙이는 경우나
아예 다른 데이터 (공통 기준이 없는 경우)를 붙여야 하는 경 사용한다.
merge()
merge 함수는 두 개의 데이터프레임을 특정 열 또는 인덱스를 기준으로 합치는 데 사용된다.
이때 join 매개변수는 두 데이터프레임에서 어떤 열을 기준으로 합칠지를 지정한다.
이 기준 열을 Primary Key(주 키)라고 부르며, 각 데이터프레임에서 해당 열의 값이 일치하는 행들을 찾아 합친다.
# merge 함수의 파라미터
1. left & right : 합치려는 두 데이터프레임을 지정 ex) pd.merge(left, right, ...)
2. on : 합치는 기준이 되는 열의 이름을 지정
3. how : 합치는 방법 지정 (inner, outer, left, right 등)
4. left_on & right_on : 합치는 두 데이터프레임에서 join 키로 사용할 컬럼 목록 지정
5. left_index & right_index : 합치는 두 데이터프레임에서 join 기준 인덱스 사용할지 여부
코드 예제로 쉽게 이해해보자
df1 = pd.DataFrame({'이름': {'홍길동','박길동','김길동','이길동'], '반':['파문응','파문기','데분기','데분중']})
df2 = pd.dataFrame({'이름':['홍길동','박길동','오길동','이길동'], '점수':[100,50,80,90]})
display(df1)
display(df2)

join을 하는 경우는 대부분 하나의 테이블, 데이터프레임에서 얻을 수 없는 결과들을
한 번에 테이블로 만들어서 다양한 데이터를 분석하기 위함이다.
예를 들어, 임의로 만든 데이터에서 반과 점수를 같이 합쳐서 길동이들의 반별 점수를 알 수 있다.
pd.merge(df1, df2, on='이름')
join 키가 두 개 이상인 경우는 어떻게 될까?
df1 = pd.DataFrame({'이름':['홍길동','박길동','김길동','이길동'], '반':['파문응','파문기','데분기','데분중'],'학번':[20,21,22,23]})
df2 = pd.DataFrame({'이름':['홍길동','박길동','오길동','이길동'], '점수':[100,50,80,90],'학번':[20,19,22,23]})
display(df1)
display(df2)

# 2개 이상을 join key로 사용
pd.merge(df1, df2, on=['이름', '학번'])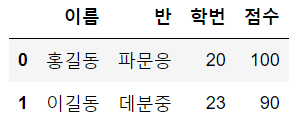
이름과 학번의 공통 교집합을 기준으로 병합된다
left_on, right_on
left_on & right_on 파라미터는 합치는 두 데이터프레임에서 join 키로 사용할 컬럼 목록 지정한다.
따라서 컬럼명은 다르지만 값이 같다면 그 내용을 지정해서 join 하게 된다.
df1 = pd.DataFrame({'이름':['홍길동','박길동','김길동','이길동'], '반':['파문응','파문기','데분기','데분중'],'번호':[20,21,22,23]})
df2 = pd.DataFrame({'이름':['홍길동','박길동','오길동','이길동'], '점수':[100,50,80,90],'학번':[20,19,22,23]})# 중복이 나오는 경우
pd.merge(df1, df2, left_on='번호', right_on='학번')
# 중복이 나오지 않는 경우
pd.merge(df1, df2, left_on='이름', right_on='이름')

left_on, right_on을 각각 '번호'와 '학번'으로 설정한 경우
join key로 잡은 것 외에 두 개의 컬럼 이름_x, 이름_y의 중복이 발생했다.
index
'index' 파라미터는 두 개의 데이터프레임을 병합할 때,
어떤 열을 기준으로 데이터를 병합할 것인지 설정하는 파라미터이다.
left_index : 왼쪽 데이터프레임의 인덱스를 사용할지 여부 결정, 기본값은 False
right_index : 오른쪽 데이터프레임의 인덱스를 사용할지 여부를 결정
인덱스는 기본 0,1,2,3, ... 순서로 되어 있는데
만약 이름을 인덱스로 지정하면
df_sp = df1.set_index('이름')
print(df_sp)
pd.merge(df_sp, df2, left_index = True, right_on='이름')
df_sp 데이터프레임 인덱스를 사용하고, df2 데이터프레임에서 병합의 기준이 되는 열을 '이름'으로 설정하여
공통의 컬럼을 기준으로 데이터를 병합하였다.
이때 주의해야 할 점은 left가 있으면
pd.merge(df_sp, df2, left_index = True)
right도 지정해야 한다는 것을 잊지 말자!
how
how 파라미터는 join 방법을 다양하게 설정할 수 있다.
inner : 공통의 교집합 컬럼을 가지고 교집합된 내용들만 병합하는 것
left : 왼쪽 데이터프레임의 join 키를 기준으로 병합
right : 오른쪽 데이터프레임의 join 키를 기준으로 병합
outer : 왼쪽과 오른쪽의 데이터프레임의 join 키에 대한 합집합을 기준으로 병합
코드 예제를 보자
# inner
pd.merge(df1, df2, on='이름', how='inner')
# left
pd.merge(df1, df2, on='이름', how='left')
# right
pd.merge(df1, df2, on='이름'. how='right')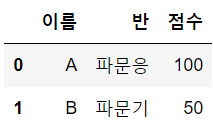
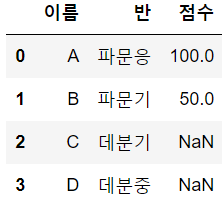
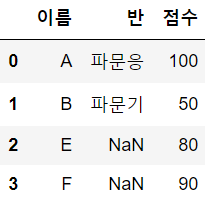
inner join을 하면 공통의 교집합 컬럼 중 교집합된 내용들만 병합한다.
left join을 하는 경우 df1의 모든 값은 고정으로 생성되고, 그 옆에 df2의 데이터 중 on 컬럼과 같은 교집합만 붙는다.
따라서 na값이 발생할 수 있음에 주의하자. (right join도 마찬가지 겠지?)
# outer
pd.merge(df1, df2, on='이름', how='outer')
outer join은 양쪽에 모두 있는 데이터와 한쪽에만 있는 데이터 모두를 포함하는 병합 방식이다.

샘플 데이터 실습
위의 개념들을 이용해서 샘플 데이터로 데이터를 병합해보자
site = pd.read_csv('survey_site.csv')
survey = pd.read_csv('survey_survey.csv')
vit = pd.read_csv('survey_visited.csv')
display(site)
display(vit)
데이터를 합병하기 전 항상 해당 데이터의 로직과 비지니스 도메인 등 데이터베이스의 설계 개념을 이해해야 한다.
그 다음으로는 어떤 컬럼을 기준(left, right, inner)으로 합병할 지 생각해야 한다.

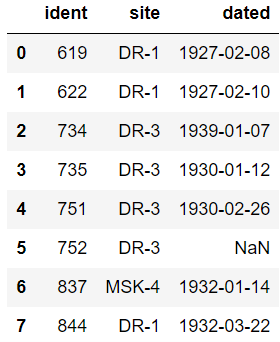
위의 데이터는 3개의 데이터를 한 번에 join하는 상황이 아닌,
하나하나씩 세 개를 하나의 테이블로 만들어야 한다.
3개의 데이터 중 vit 데이터는 메타데이터로, 다른 데이터를 설명하는 정보를 나타낸다.
이러한 데이터와 같이 메타스키마의 개념(DB 등에서 사용되는 데이터 스키마에 대한 메타데이터를 기술하는 구조)에서는
전체를 관리하는 테이블이 항상 존재한다.
이제 각각의 데이터를 join 해보자
# site, vit 데이터를 name과 site 기준으로 먼저 병합
mg1 = pd.merge(site, vit, left_on=['name'], right_on=['site'])
# 병합한 데이터를 survey 데이터와 적절한 join key로 병합
pd.merge(mg1, survey, left_on=['ident'], right_on=['taken'])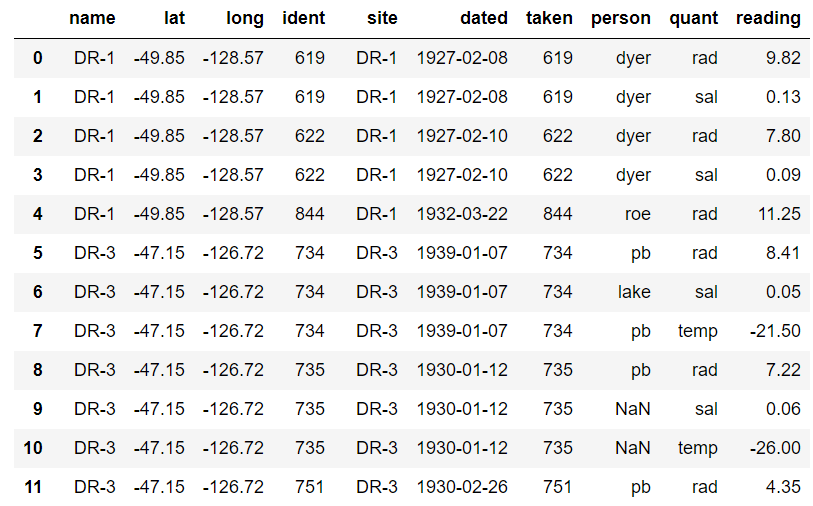
오늘 내용은 너무 어려워서 앞으로 계속 공부가 필요할 것 같다..
'Tools & Skills > Python' 카테고리의 다른 글
| seaborn 라이브러리 연습 (1) | 2024.01.21 |
|---|---|
| 데이터 전처리 문법 중급 (0) | 2024.01.12 |
| Outlier! (0) | 2024.01.12 |
| 결측치와 누락값 (2) | 2024.01.07 |
| 데이터 전처리 기본기 (0) | 2024.01.02 |