2024. 1. 12. 17:46ㆍTools & Skills/Python
이번 포스팅에서는 시계열 데이터 전처리에서 사용되는 문법을 다뤄본다.
# 파일 불러오기
import pandas as pd
df = pd.read_csv('gapminder.tsv', sep='\t')
1. Groupby
1주차에서 배운 Groupby() 함수는 시계열 데이터에서도 유용하게 사용한다.
# 바로 컬럼을 지정하여 통계치를 볼 수 있다.
df.groupby('year').lifeExp.mean()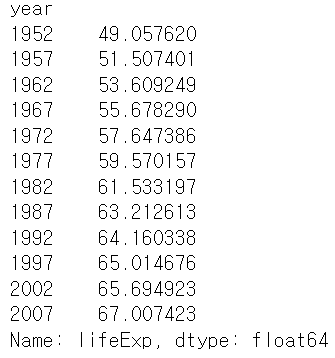
만약 컬럼을 2가지 이상 잡게 된다면?
df.groupby('year')[['lifeExp', 'pop']].mean()
1주차에서 groupby() 함수는 .agg() 함수와 자주 함께 사용된다는 것을 배웠다.
.agg() 함수는 내가 원하는 함수를 만들어서 넣을 수 있다는 것을 명심하자!
# 내가 원하는 함수를 만들어 넣을 수 있다
def my_mean(values):
n = len(values)
sum_1 = 0
for value in values:
sum_1 += value
return sum_1/n
df.groupby('year').lifeExp.agg(my_mean)
또, numpy 라이브러리를 이용해서 agg 함수에 추가할 수도 있다.
import numpy as np
df.groupby('year').lifeExp.agg([np.mean, np.std, np.count_nonzero])
2. merge
merge()함수는 기본적으로 데이터와 데이터를 합치는 경우에 사용한다.
데이터분석(DA) 영역에서는 SQL로 충분히 가능하지만,
데이터과학(DS) 영역 데이터셋을 정제하는 과정에서는 pandas를 많이 사용한다.
임의로 데이터를 만들어서 사용해보자
test1 = pd.DataFrame({'class':['파문기','데분기','데분중','데분고'],
'인원':[100,200,300,40]})
test2 = pd.DataFrame({'class':['파문기','데분기','데분중','데분고'],
'벌점평균':[5,6,7,3]})
print(test1)
print(test2)
class에 따라 인원, 벌점평균을 같이 볼 수 있는 테이블을 만드는 경우
join 개념을 통해 공통의 키로 가지고 가서 class를 잡고 병합을 한다.
# how : 조인의 방법 = left join, right join, inner join, outer join
# on : 공통의 컬럼
pd.merge(test1, test2, how='left', on='class')
3. concat
concat() 함수는 merge()와 합치는 개념은 같지만,
공통적인 키를 잡는 것이 아닌 테이블-테이블 or 덩어리-덩어리 두 개가 붙는 개념이다.
sp = pd.concat([test1, test2], axis=1) # 공통적인 컬럼을 지정하지 않는다.
print(sp)
4. loc, iloc
데이터에 접근하는 방법 중 loc, iloc이 있다.
loc: 인덱스를 기준으로 데이터를 접근하는 방식, 컬럼의 이름 그대로 가져올 수 있다
iloc: 행의 순서에 따라 데이터를 접근하는 방식, 컬럼을 숫자로 대체해서 가져와야 한다
df_sp = df[0:100:2]
print(df.loc[0:100])
print(df.iloc[1])

5. melt()
통계청 데이터들을 보면 컬럼들이 날짜로 나열되고 있고,
이 부분을 행으로 바꾸면 더욱 깔끔하게 데이터를 볼 수 있다.
이때 컬럼의 여러가지 의미가 있는 데이터의 경우 좀 더 깔끔하게 만드는 법이 있다.
pew = pd.read_csv('pew.csv')
pew
melt() 함수를 사용할 때는 기준을 잡는 설정이 존재한다.
# 기준
id_vars : 위치 그대로 유지할 열의 이름 지정
value_vars : 행으로 위치를 변경할 열의 이름
var_name value_vars : 위치로 변경한 열의 이름 지정
value_name var_name : 위치로 변경한 열의 이름지정
pd.melt(pew, id_vars='religion', var_name='income', value_name='count')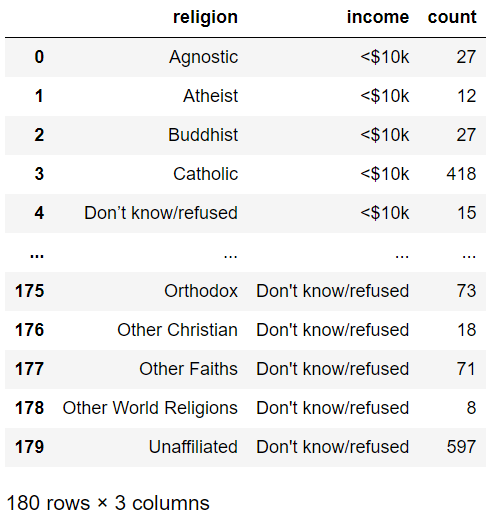
6. 피처 엔지니어링
위에서 살펴본 데이터처럼 컬럼의 여러가지 의미가 있는 데이터의 경우
컬럼을 나눠서 새로운 컬럼을 만들거나, 피처엔지니어링 개념으로 접근해서 파생변수를 만들 수 있다.
ebola = pd.read_csv('country_timeseries.csv')
# case 1: melt 함수 이용
ebola_pre = pd.melt(ebola, id_vars['Date', 'Day'])
# case 2: str 문법 중 split 함수를 이용해서 나눌 수 있다.
ebola_pre_sp = ebola_pre.variable.str.split('_')
# case 3: 각 행의 문자열에서 추출하여 새로운 열에 추가
ebola_pre['case']= ebola_pre_sp.str.get(0)
ebola_pre['country'] = ebola_pre_sp.str.get(1)


'Tools & Skills > Python' 카테고리의 다른 글
| seaborn 라이브러리 연습 (1) | 2024.01.21 |
|---|---|
| 데이터 병합 (1) | 2024.01.15 |
| Outlier! (0) | 2024.01.12 |
| 결측치와 누락값 (2) | 2024.01.07 |
| 데이터 전처리 기본기 (0) | 2024.01.02 |