2024. 1. 12. 16:10ㆍTools & Skills/Python
이상치(Outlier)
이상치(Outlier)란, 보통 관측된 데이터의 범위에서 많이 벗어난 작은 값이나 큰 값을 말한다.
극단적인 값이고, 전체 데이터 범위를 넘는 값이므로 이 데이터를 무조건 제거해야 하는가?
라는 질문에 대한 답을 한다면 글쎄..
예를 들어, 백화점 고객데이터에서 일반고객과 vip고객의 데이터를 비교하면 vip 고객은 outlier일 것이다.
그러나, 백화점 입장에서 보면 Outlier에 속해있는 vip고객 데이터를 더 집중해야하는 고객이라 판단하고, 이 부분에 대해 고민해야 한다.
즉, 데이터 분포가 outlier와 기존의 데이터분포로 나눠진다면
과연 outlier 의미가 이상치인지 의미있는 데이터인지 의심을 해봐야 하는 것!
이상치 처리
이러한 이상치가 의사결정에 큰 영향을 미칠 수 있기 때문에 데이터 전처리 과정에서의 적절한 이상치 처리는 필수적이다.
주의해야 할 점은 어떤 정답이 있는 방법이 아니기 때문에 목적에 맞는 이상치 제거에 대한 방법을 생각해야 한다.
= 단순하게 수치적으로만 접근해서 이상치를 제거하고 성능을 높이고 일반화를 할 수 없는 것!
임의로 각 반의 수학 점수 데이터를 만들어서 쉽게 이해해보자
# 각 반의 수학 점수
t_math1 = [50, 30, 22, 45, 63, 80, 20, 31, 15, 40, 100]
t_math2 = [80, 65, 10, 21, 22, 25, 10, 9, 12, 7, 100]
# 데이터프레임 생성
df = pd.DataFrame({'scoring_1':t_math1,
'scoring_2':t_math2})
sns.scatterplot(data = df.scoring_1)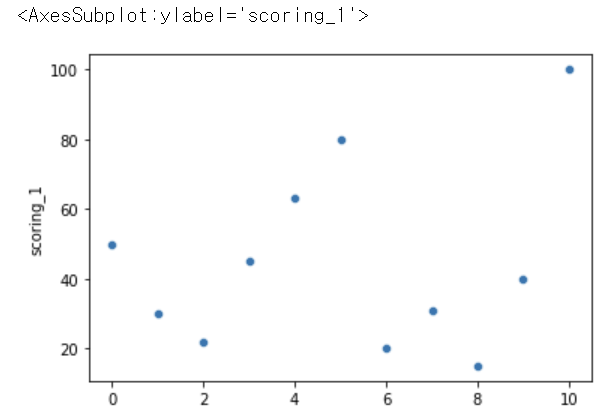

수학 점수 분포 중 100점은 이상치가 아니라 충분히 나올 수 있는 점수이므로 제거 하면 안된다.
예시 데이터를 가지고 outlier를 확인하기
from sklearn import datasets
dataset = datasets.fetch_california_housing()
df = pd.DataFrame(dataset.data, columns = dataset.feature_names)
df['target'] = dataset.target
df.head()캘리포니아 집값 데이터를 이용하여 이상치를 확인해보자

1. boxplot & 통계치 확인
sns.boxplot(y = df.target) # target column 이상치 확인
df.target.describe() # target column 통계치 분석

sns.boxplot(y=df.AveRooms) # AveRooms 이상치 확인
df.AveRooms.describe() # AveRooms 통계치 분석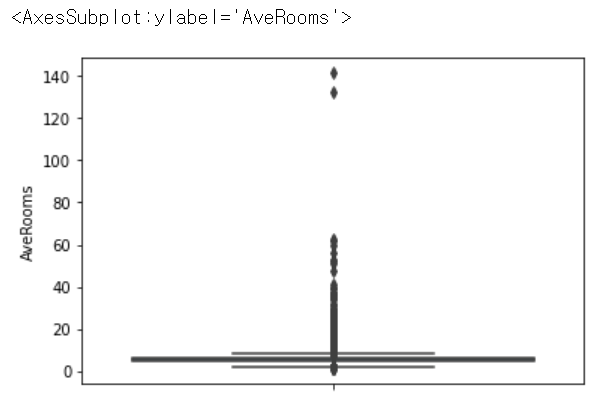

2. 베이스라인 모델 회귀분석
boxplot과 통계치 확인으로 이상치를 확인해봤다.
그렇다면 이상치를 제거하지 않고 회귀분석의 RMSE 정도를 낮출 수는 없는지 베이스라인 모델로 확인해보자
베이스라인 모델은 회귀분석에서의 간단한 예측 모델로, 주로 모든 입력에 대해 평균값이나 중앙값을 반환하는 경우가 많다. 따라서 특정 문제에 대해 복잡한 패턴을 고려하지 않고, 머신러닝 모델의 성능을 평가할 때 사용된다.
import statsmodels.api as sm
import matplotlib.pyplot as plt
fit_train1 = sm.OLS(y_train, x_train)
fit_train1 = fit_train1.fit()
# 예측한 값
plt.plot(np.array(fit_train1.predict(x_test)), label='pred')
plt.plot(np.array(y_test), label='True')
plt.legend()
plt.show()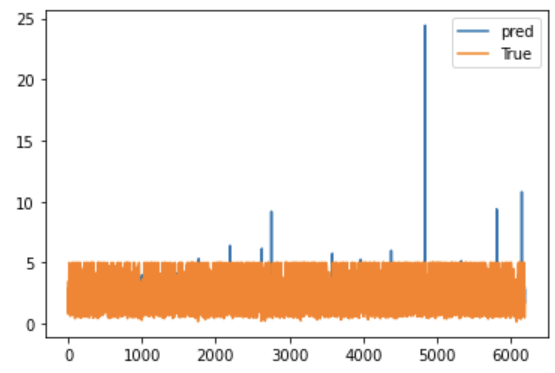
베이스라인으로 회귀분석을 진행하여 시각화한 결과
유의미한 해석을 내리기엔 무리가 있다.
모델의 mse 수치를 확인해보자
# mse 수치 확인
from sklearn.metrics import mean_squared_error
mse1 = mean_squared_error(y_true = y_test, y_pred = fit_train1.predict(x_test))
print(mse1)1.3737537935478012
베이스라인 모델로 회귀분석 진행 시 mse 수치는 1.37
IQR(사분위수 범위)
다른 포스팅에서 다룰 예정이지만, IQR에 대한 개념을 간단히 짚고 넘어가자
IQR은 이상치에 레이블을 지정하는 방법으로, 사분위수(데이터를 동일한 크기의 4개 그룹으로 나누는 지점)을 사용한다.

상자 수염 그림은 사분위수를 사용하여 데이터 모양을 그리는데,
상자는 제 1사분위와 제 3사분위를 나타내며, 각각 백분위 25%와 75%와 같다. 내부 선은 제 2사분위수를 나타낸다.
3. IQR 제거
이번에는 AveRooms columns의 이상치 제거를 통계치에 대한 개념으로 진행해보자
Q1 = df_sp['AveRooms'].quantile(0.25)
Q3 = df_sp['AveRooms'].quantile(0.75)
IQR = Q3 - Q1
rev_range = 3
# IQR 제거를 위한 필터 생성
filter1 = (df_sp['AveRooms'] >= Q1 - rev_range * IQR) & (df_sp['AveRooms'] <= Q3 + rev_range * IQR)
df_sp_rmv = df_sp.loc[filter1] # IQR 제거를 완료한 후 column만 df_sp_rmv에 저장
df_sp_rmv
4. 이상치 제거
이번에는 백분위수를 계산하여 이상치를 식별한뒤 np.nan으로 대체하여 제거할 것이다.
def replace_outlier(value):
Q1 = df_sp['AveRooms'].quantile(0.25) # quantile(q): 이 부분은 'AveRooms' 열의 데이터에 대한 백분위 수를 계산하는 메서드를 호출하는 부분
Q1 = df_sp['AveRooms'].quantile(0.75)
IQR = Q3 - Q1
rev_range = 3
if((value < (Q1-rev_range*IQR))):
value = np.nan
if((value > (Q3+rev_range*IQR))):
value = np.nan
return value
df_sp['AveRooms'] = df_sp['AveRooms'].apply(replace_outlier)
'replae_outlier' 함수는 df_sp의 'AveRooms'열의 이상치를 식별하고 교체하는 기능을 한다.
코드가 정상 작동됐는지 확인하자
df_sp.isna().sum()
이제 이상치를 제거하고 회귀분석 해보자!
df_sp2 = df_sp.dropna() # 이상치 제거
# 이상치를 제거한 train, test 나누기
x_train, x_test, y_train, y_test = train_test_split(df_sp2.drop('target', axis=1), df_sp2['target'], test_size=0.3, random_state=111)
import statsmodels.api as sm
import matplotlib.pyplot as plt
fit_train1 = sm.OLS(y_train, x_train)
fit_train1 = fit_train.fit()
# 예측한 값
plt.plot(np.array(fit_train1.predict(x_test)), label='pred')
plt.plot(np.array(y_test), label='True')
plt.legend()
plt.show()
시각화로 비교하긴 어려우므로
mse 수치로 비교해보자
from sklearn.metrics import mean_squared_error
mse2 = mean_squared_error(y_true = y_test, y_pred = fit_train1.predict(x_test))
print(mse2)1.1694755604062264
앞서 확인한 베이스라인 모델의 mse 수치를 비교해볼때 더 낮은 수치를 보이는 것을 확인할 수 있다.
그렇다면 만약 이상치를 살려서 분석을 진행하는 경우는 어떤 식으로 하면 되는가?
1. 이상치에 가중치 1, 이상치가 아닌 경우 가중치 0
2. 이상치 가중치 0, 이상치가 아닌 경우 가중치 1
def saving_outlier(value):
Q1 = df_sp['AveRooms'].quantile(0.25)
Q2 = df_sp['AveRooms'].quantile(0.75)
IQR = Q3 - Q1
rev_range = 3
if((value < (Q1 - rev_range * IQR))): # 이상치라면
value = 1 # 가중치 1
elif((value > (Q3 + rev_range * IQR))):
value = 1
else:
value = 0 # 이상치가 아니면 가중치 0
df_sp['AveRooms_sv'] = df_sp['AveRooms'].apply(saving_outlier)
df_sp.AveRooms_sv.sum()180
마찬가지로 회귀분석 진행 후 mse 수치 비교!
# 이상치를 제거한 train, test 나누기
x_train, x_test, y_train, y_test = train_test_split(df_sp.drop('target', axis=1), df_sp['target'], test_size=0.3, random_state=111)
import statsmodels.api as sm
import matplotlib.pyplot as plt
fit_train3 = sm.OLS(y_train, x_train)
fit_train3 = fit_train3.fit()
# 예측한 값 시각화
plt.plot(np.array(fit_train3.predict(x_test)), label='pred')
plt.plot(np.array(y_test), label='True')
plt.legend()
plt.show()
# mse 수치 확인
from sklearn.metrics import mean_squared_error
mse3 = mean_squared_error(y_true = y_test, y_pred = fit_train3.predict(x_test))
print(mse3)
# mse 수치
1.3195403300827173
3가지 방법의 mse 수치를 비교해보자
print(mse1, '기존 base')
print(mse2, 'outlier 제거')
print(mse3, 'outlier saving')
1.3737537935478015 기존 base
1.1694755604062266 outlier 제거
1.3195403300827173 outlier saving
참고
IQR(사분위수 범위)
IQR은 이상치에 레이블을 지정하는 다른 강력한 방법입니다. IQR(사분위수 범위) 이상치 감지 방법은 탐색 데이터 분석의 선구자인 John Tukey가 개발한 것입니다. 이 방법은 수동으로 계산하고 그래
docs.oracle.com
'Tools & Skills > Python' 카테고리의 다른 글
| 데이터 병합 (1) | 2024.01.15 |
|---|---|
| 데이터 전처리 문법 중급 (0) | 2024.01.12 |
| 결측치와 누락값 (2) | 2024.01.07 |
| 데이터 전처리 기본기 (0) | 2024.01.02 |
| BeautifulSoup 맛 보기 (0) | 2023.12.19 |