2024. 1. 8. 13:28ㆍData Analysis/ML Modeling
보간법을 사용하여 결측치를 보간하고, sklearn-impute 라이브러리를 이용해서 회귀분석을 진행해보자
회귀분석을 통해 mse 차이 비교
1) 필요한 패키지 임포트
# sklearn-learn에서 일부 실험적이거나 미완성 기능 사용 시 experimental 모듈 제공
# 명시적으로 활성화해야만 사용할 수 있음
# Imputeation 대체 방법을 사용하는 Imputer 활성화
from sklearn.experimental import enable.iterative_imputer
# 결측값 예측에 회귀 모델을 반복적으로 사용하여 결측값을 대체하는 도구 임포트
from sklearn.impute import IterativeImputer
import pandas as pd
import seaborn as sns
import numpy as np
2) 데이터셋 불러오기
실습에는 차량 연비 데이터셋 mpg를 사용한다.
# mpg 데이터셋 컬럼 설명
연비 - mpg
실린더 - cylinders
배기량 - dispalcement
마력 - horsepower
무게 - weight
제로백 - acceleration
df = sns.load_dataset('mpg')
df
지난 시간에 배웠던 결측치를 대체하는 방법 중
평균대치, 선형보간의 방법과 sklearn iterative imputer를 사용해서 실제 결측값을 대체하고
해당 결측값을 대체한 것을 회귀분석을 통해 MSE차이가 어떤 식으로 나오는지 비교하려고 한다.
평균제곱오차(Mean Squared Error, MSE)
평균제곱오차(MSE)는 예측값과 실제값 간의 차이를 측정하는 방법 중 하나로,
이름에서 알 수 있듯이 오차(error)를 제곱한 값의 평균이다.
오차란 알고리즘이 예측한 값과 실제 정답과의 차이를 의미한다.
즉, 알고리즘이 정답을 잘 맞출수록 MSE 값은 작아지고, MSE값이 작을수록 알고리즘의 성능이 좋다고 볼 수 있다.


MSE 특징 및 해석
✔️ 오차 제곱의 평균을 측정 : 예측값과 실제값 간의 편차를 잘 나타냄
✔️ 제곱 오차에 대한 민감도 : 큰 오차에 더 민감, 따라서 큰 오차에 큰 페널티를 줌
✔️ 값 범위 : MSE 값은 항상 양수, 0에 가까울수록 모델의 예측이 실제값과 일치
3. 결측치 확인 & 독립변수 추출
df.isna().sum()
결측치를 확인했으니 제거하고, 회귀분석에 필요한 columns를 추출한다.
이때, 예측값이 될 결측치가 존재하지 않으므로 임의로 결측치를 만들어야 한다.
df.dropna(inplace=True)
# 필요한 columns만 따로 df_x 변수에 저장
df_x = df[['cylinders', 'displacement', 'horsepower', 'weight']]
## 결측치를 임의로 만들어야 하는 상황
msv = np.random.randint(0,389, size=30) # 0부터 388까지 랜덤한 정수를 갖는 길이가 30인 배열 생성
# df_x에서 msv에 해당하는 행을 선택하고 해당 행의 모든 열을 NaN(결측치)으로 설정
df_x.iloc[msv] = np.nan
df_x.isna().sum()
4. 새로운 변수 생성
연비 'mpg' 변수 열과 예측에 필요한 독립변수 열을 포함하여 새로운 df_sp를 생성한다.
이때, 각각의 df_sp 변수는 다른 보간 방법을 적용할 것이다.
df_sp1 = pd.concat([df_x, df['mpg']], axis=1) # axis=1는 열 방향으로 합치는 의미
df_sp2 = pd.concat([df_x, df['mpg']], axis=1)
df_sp3 = pd.concat([df_x, df['mpg']], axis=1)
5. 실제 예측
5.1 결측치를 평균으로 대체
실제 예측을 위해 먼저 결측치를 평균으로 대체하는 방법부터 사용한다.
먼저 평균을 알아보자
df_x.cylinders.mean() # 평균 확인
df_x.displacement.mean()
df_x.horsepower.mean()
df_x.weight.mean()
5.450549450549451 # cylinders.mean
192.78434065934067 # displacement.mean
104.12362637362638 # horsepower.mean
2963.684065934066 # weight.mean
이제 결측치를 평균으로 대체해보자
df_sp1['cylinders'] = df_sp1['cylinders'].fillna(df_x.cylinders.mean())
df_sp1['displacement'] = df_sp1['displacement'].fillna(df_x.displacement.mean())
df_sp1['horsepower'] = df_sp1['horsepower'].fillna(df_x.horsepower.mean())
df_sp1['weight'] = df_sp1['weight'].fillna(df_x.weight.mean())
df_sp1.isna().sum() # 결측치 확인
실제 예측 고고
# 데이터 세트 분리
from sklearn.model_selection import train_test_split
# df_sp1에서 'mpg' 열을 제외한 나머지 열들을 특성으로, 'mpg' 열을 타겟으로 사용하여 데이터 나눔
x_train, y_test, y_train, y_test = train_test_split(df_sp1.drop('mpg', axis=1), # 'mpg' 열 제외 나머지 열들을 입력 변수 'x'에 저장
df_sp1['mpg'], # 'mpg'열을 타겟으로 하는 Series 생성, 출력 변수 'y'에 해당
test_size = 0.3, # 전체 데이터 중 테스트 세트로 사용할 비율, 즉 30%가 테스트 세트로 사용
random_state=111) # 난수 발생을 위한 시드 값
import statsmodels.api as sm # 회귀 분석에 필요한 모듈
import matplotlib.pyplot as plt # 시각화 모듈
# 회귀분석 진행 (다중회귀)
fit_train1 = sm.OLS(y_train, x_train) # OLS 모델 생성, y_train(종속 변수), x_train(독립 변수)
fit_train1 = fit_train1.fit() # OLS 모델을 훈련 데이터에 대해 최적의 회귀 계수를 찾게함
# 실제 예측
plt.plot(np.array(fit_train1. predict(x_test)), label='pred')
plt.plot(np.array(y_test), label='True')
plt.legend()
plt.show()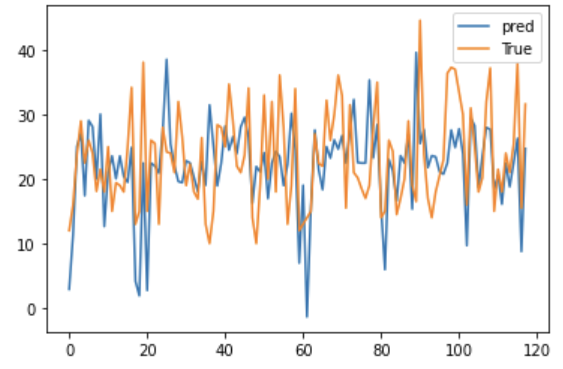
모델의 성능을 확인하기 위해 MSE수치를 확인해보자
from sklearn.metrics import mean_squared_error
mse1 = mean_squared_error(y_true = y_test, y_pred = fit_train1.predic(x_test))
print(mse1)
57.28585514238014
# 평균을 가지고 대체해서 나온 회귀식 예측결과 실제값과 예측값의 mse는 약 57.28
5.2 선형보간법
이번에는 결측치를 선형보간을 진행하여 회귀분석을 진행해보자
df_sp2['cylinders'] = df_sp2['cylinders'].interpolate(method='linear')
df_sp2['displacement'] = df_sp2['displacement'].interpolate(method='linear')
df_sp2['horsepower'] = df_sp2['horsepower'].interpolate(method='linear')
df_sp2['weight'] = df_sp2['weight'].interpolate(method='linear')
df_sp2.isna().sum()
앞서 평균으로 대체했을 때 진행한 방법과 동일하게 진행한다.
# 데이터 세트 분리
x_train, x_test, y_train, y_test = train_test_split(dp_sp2.drop('mpg', axis=1), df_sp2['mpg'], test_size=0.3, random_state=111)
# 회귀분석 진행 (다중 회귀)
fit_train2 = sm.OLS(y_train, x_train)
fit_train2 = fit_train2.fit() # fit 모델 만들고
# 실제 예측 진행
plt.plot(np.array(fit_train1.predict(x_test)), label='pred')
plt.plot(np.array(y_test), label='True')
plt.legend()
plt.show()
모델의 성능을 확인하기 위해 MSE 수치를 확인해보자
from sklearn.metrics import mean_squared_error
mse2 = mean_squared_error(y_true = y_est, y_pred = fit_train2.predict(x_test))
print(mse2)
55.84782537189774
선형보간을 진행하다보니 실제 평균으로 대체하는 것 보다는 더 낮은 mse값이 나왔다.
5.3 IterativeImputer
sklearn 라이브러리에서 제공하는 결측치 대체 도구 중
IterativeImputer는 반복적인 접근을 통해 결측치를 예측하고 채워넣는 방법을 사용한다.
여러 반복을 통해 결측치를 예측하는 방법은 다음과 같다.
1. 각 변수(특성)에 대해 초기 예측값을 설정
2. 반복적으로 예측값을 업데이트하고, 결측치를 채워넣음
3. 일정한 횟수나 수렴 조건이 만족될 때까지 2번의 단계를 반복
이 방법은 각 변수의 결측치를 해당 변수의 다른 변수들을 사용하여 예측하는데, 반복을 통해 개선해나간다.
이는 변수 간의 상호 작용을 고려하여 결측치를 대체 할 수 있는 장점이 있다.
이 방법으로 결측치를 대체해보자
Imputer = IterativeImputer(imputation_order = 'descending', # 결측치 대체를 어떤 순서로 수행할지 지정
max_iter=10, # 반복 횟수를 제어하는 매개변수로, 결측치 대체를 수행하는 최대 반복 횟수 지정
random_state=111, # 시드 생성
n_nearest_features=4) # 결측치 예측에 사용할 최근접 이웃의 수, 결측치 예측 시 해당 변수와 가장 유사한 특성들을 사용
df_sp3 = imputer.fit_transform(df_sp3) # 결측치 대체
df_sp3

그러나 이 방법의 반환값은 array 형태로 만들어지므로 데이터프레임으로 변환이 필요하다.
# 데이터프레임으로 변환
df_sp3 = pd.DataFrame(df_sp3)
# Column 이름 지정
df_sp3.columns = ['cylinders', 'displacement', 'horsepower', 'weight', 'mpg']
# 데이터프레임 변환 결과 확인
df_sp3
이제 회귀분석을 진행해보자
x_train, x_test, y_train, y_test = train_test_split(df_sp3.drop('mpg', axis=1), df_sp3['mpg'], test_size=0.3, random_state=111)
fit_train3 = sm.OLS(y_train, x_train)
fit_train3 = fit_train3.fit()
# 실제 예측
plt.plot(np.array(fit_train3.predict(x_test)), label='pred')
plt.plot)np.array(y_test), label='True')
plt.legend()
plt.show()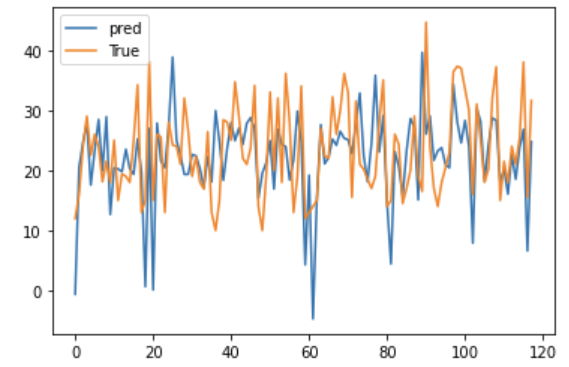
모델의 성능을 확인하기 위해 MSE 수치를 확인해보자
mse3 = mean_squared_error(y_true = y_test, y_pred = fit_train3.predict(x_test))
print(mse3)
51.95993279347955
결측치를 대체한 방법 3가지의 mse 수치를 비교해 모델의 성능을 비교해보자
print(mse1, '단순평균대치법')
print(mse2, '선형보간법')
print(mse3, 'Iterative Imputer')
57.28585514238014 단순평균대치법
55.84782537189774 선형보간법
51.95993279347955 Iterative Imputer
Iterative Imputer 메서드를 사용하여 결측치를 대체한 경우 가장 mse 수치가 높게 나왔다.
결과 해석
단순 MSE수치를 비교하였을 때는 sklearn 라이브러리 대치 방법이 가장 낮게 나왔다.
그러나 모든 데이터를 이런 식으로 sklearn 대치하는 것이 가장 좋은 방법이라고 말할 수는 없다.
데이터의 관계나 데이터의 분포, 더 나아가서는 앞단의 데이터에 대한 도메인 지식이 필수적으로 있어야 한다.
데이터 분석가가 도메인 지식없이 단순하게 수치로만 싸우게되면 결국 이런 수치만 보고 판단하는 오류를 범하게 된다.
이를 방지하기 위한 가장 중요한 것은 현재 데이터 분포에 대한 정확한 이해와 도메인 마다 결측치를 대체하는 방법의 로직의 이해이다.
참고
[Hey Tech- 평균제곱오차 개념 및 특징]https://heytech.tistory.com/362
[Deep Learning] 평균제곱오차(MSE) 개념 및 특징
💡 목표 평균제곱오차(MSE)의 개념과 특징에 대해 알아봅니다. 1. MSE 개념 평균제곱오차(Mean Squared Error, MSE)는 이름에서 알 수 있듯이 오차(error)를 제곱한 값의 평균입니다. 오차란 알고리즘이 예
heytech.tistory.com
'Data Analysis > ML Modeling' 카테고리의 다른 글
| [Bias-Variance Trade-off] 19분 예상 도착? 기사님 빨리가주세요! (0) | 2025.01.20 |
|---|