2023. 12. 19. 15:50ㆍ나의 군 시절
다음 두 문장을 비교해보자.
"고양이는 쥐를 먹는다."
"쥐는 고양이의 밥을 먹는다."
인간은 쉽게 차이를 구별하지만, 컴퓨터가 이해하려면?
정확한 문맥 파악을 하지 않으면 쉽지 않을것이다.
두 개의 문장이 얼마나 유사한지 어떻게 분석할 수 있을까?
바로 텍스트 유사성 분석이다.
텍스트 유사성 분석
온라인 쇼핑 플랫폼에 작성된 질문들을 보면 다음과 같은 질문들을 많이 봤을 것이다.
"언제 상품을 받아볼 수 있을까요?"
"상품 도착 예정일을 알려주세요."
두 문장은 다른 어휘를 사용했지만, 의미적으로는 매우 유사하다.
텍스트 유사성 분석은 어휘적 유사성과 의미적 유사성을 비교했을때
얼마나 가까운지 확인하기 위해 시행한다.
정확한 문맥 파악을 위해서 문장 임베딩은 이러한 차이에 민감해야 한다.
임베딩이 뭘까요
임베딩은 사람이 쓰는 자연어를 기계가 이해할 수 있도록
숫자형태인 Vector로 바꾼 결과 혹은 그 전체 과정을 말하고,
다음 그림처럼 단어와 같은 데이터 조각을 벡터로 변환해 벡터 공간에 끼워 넣는다는 의미이다.
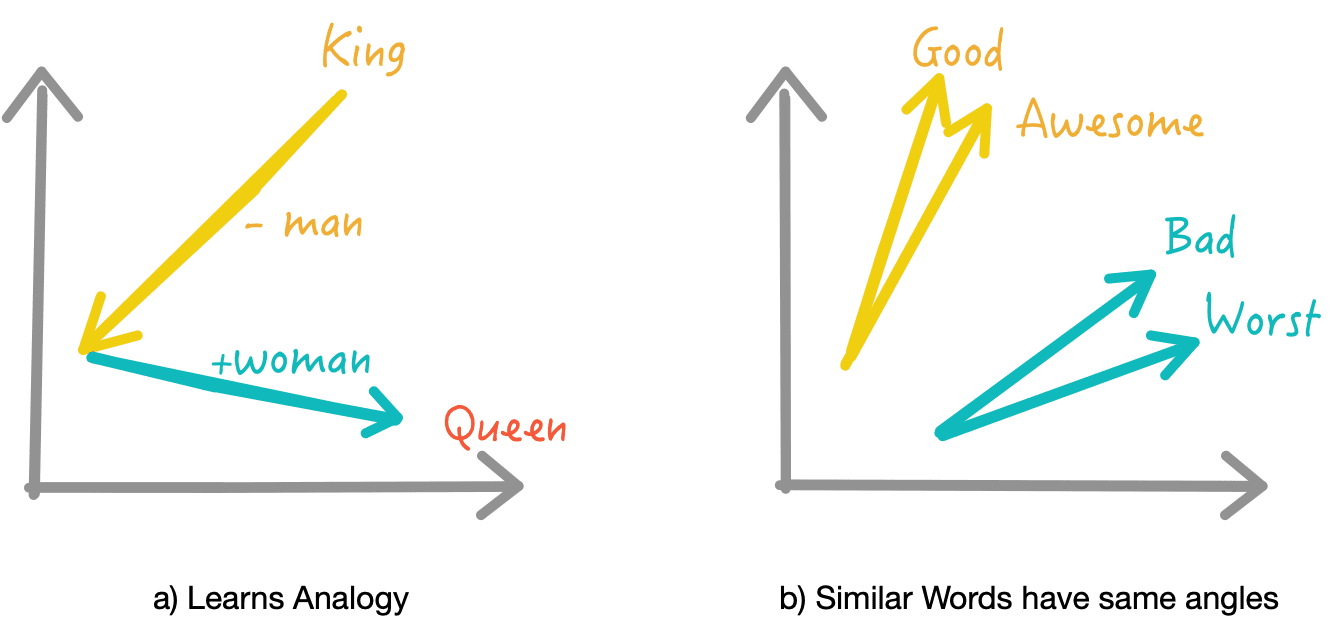
<출처 [AI - "WORD EMBEDDING"](https://alasheep.com/blog/2020/07/22/word-embedding/) >
임베딩은 여러 방식이 있지만, 가장 간단한 형태는 단어의 빈도를 그대로 벡터로 변환하는 방식이다.
문장 속 단어들의 출현 빈도를 숫자로 변환시키면 비교분석이 쉬울테니까!
간단하게 단어-문서 행렬로 분석해보자.
| 구분 | 문서 A | 문서 B | 문서 C |
| 단어 i | 0 | 3 | 4 |
| 단어 j | 1 | 0 | 0 |
| 단어 k | 1 | 0 | 0 |
# 단어-문서 행렬 분석
분석 1:
문서 B와 문서 C에는 단어 i가 많이 포함되어 있는 것으로 보아,
두 문서의 내용은 비슷할 것으로 추측가능
분석 2:
단어 j와 단어 k는 문서 A에 같이 등장한 것으로 보면,
두 단어는 단어 i와 단어 k의 의미 차이보다 적다는 것 역시 추측가능
이처럼 문서나 단어를 벡터로 변환시킨 값 또는 그 과정 자체 = 임베딩!
그렇다면 임베딩의 역할은 다음과 같이 정리할 수 있을 것 같다.
임베딩의 역할
✔ 단어/문장 간 관련도 계산
✔ 의미적/문법적 정보를 함축
✔ 전이 학습을 위한 임베딩
그럼 당연히 변환시킨 벡터 값이 본래의 정보와 의미를 잘 담아낼수록 좋은 임베딩이겠지?
임베딩의 방법에는 여러가지가 있지만, 오늘은 수업에서 다룬 TF-IDF 방식만 맛 봐보자.
TF-IDF
다음 글에서 중요한 단어를 모두 말해보시오. (3점)
제목: 과일 가게
과일가게에서 사과, 바나나를 팔고있다.
그 중에서 사과가 제일 맛있다.
다음으로는 바나나가 맛있다.
💬 : (자주 나온 단어 중에서..) 사과, 바나나
TF-IDF는 위 답변을 떠올린 생각처럼
어떤 문장의 구성요소가 문서에서 어떤 중요도를 가지는지에 따라 가중치를 주는 통계적 표현 방법이다.
단어 수를 그대로 카운트 하지 않고,
`사과`, `바나나` 처럼 특정 문서에서만 빈출하는 단어는 가중치를 주고,
많은 문서에 공통적으로 들어있는 단어(`에서`, `를` ...)의 경우
문서 구별 능력이 떨어진다고 보아 가중치를 축소한다.
TF-IDF 가중치 계산 방법
문서 d와 단어 t에 대해,
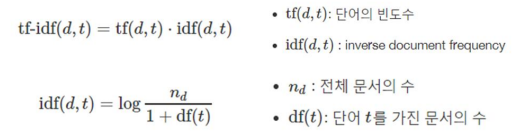
단어 출현빈도(Term Frequency, TF)와 역 문서 빈도(Inverse Document Frequency, IDF)를 곱하여
단어마다 TF-IDF 가중치를 부여한다.
DF는 오직 단어가 몇 개의 문서에 출현했는지만 궁금해 하고,
IDF는, 쉽게 df(t): 단어 t를 가진 문서의 수 값의 역수이다.
예를 들어, 문서 A, B, C, D가 있는데
단어 X가 문서 A에서 100번, B에서 200번 등장했더라도
전체 문서에서 단어가 등장한 개수, 즉 Df값 = 2
따라서 DF값이 작아지면, TF-IDF값이 증가하고 해당 단어(t)의 중요도가 UP
강의 수강 중 궁금증: IDF 수식 이해
강의를 들으면서 IDF의 수식을 보는데 이해가 안되는게 두 가지가 있었다.
Q1. IDF는 DF의 역수인데 왜 분모를 1을 더하는지..
A. 로그 내 분모에 1을 더하는 이유
: 특정 단어 t가 전체 문서에서 출현하지 않는 경우,
분모가 0이 되는 상황(ZeroDivisonerror)를 방지하기 위함.
Q2. 또 로그는 왜 씌우지..
A. 로그 사용이유
문서 개수D가 늘어날수록
문서 내 빈출 단어와 희귀 단어에 부여되는 가중치 차이를 줄이기 위해 로그를 사용
= 불용어와 희귀 단어는 출현 빈도 차이가 매우 심해 문서 개수가 늘어날수록 IDF값이 매우 커짐.
참고
[임베딩이 뭐지? - Feel's blog](https://casa-de-feel.tistory.com/28)
[임베딩(Embedding)이란? - 백지에서 깜지까지.log](https://velog.io/@glad415/%EC%9E%84%EB%B2%A0%EB%94%A9Embedding%EC%9D%B4%EB%9E%80)
[[NLP] TF-IDF 개념 및 계산 방법(+Python 코드) - Hey Tech](https://heytech.tistory.com/337)
'나의 군 시절' 카테고리의 다른 글
| 나는 나랑 닮은 사람이 좋아. (0) | 2023.12.29 |
|---|---|
| Darknight 리뷰 Exploration & Visualization (2) | 2023.12.29 |
| Preprocessing Text Data (2) | 2023.12.27 |
| 개발자 도구 & Web Scraping 프로세스 (0) | 2023.12.19 |
| Web Scarping & HTML 기초 (2) | 2023.12.19 |