2023. 12. 19. 14:38ㆍ나의 군 시절
개발자 도구
네이버에 데이터분석을 검색 후 뉴스 기사를 들어간 후
페이지의 아무 부분에 커서를 대고 마우스 오른쪽 클릭을 하면
페이지 소스 보기 항목이 나온다.
항목을 누르면 다음과 같은 HTML 코드가 쭉 작성된 페이지가 새로 나타난다.
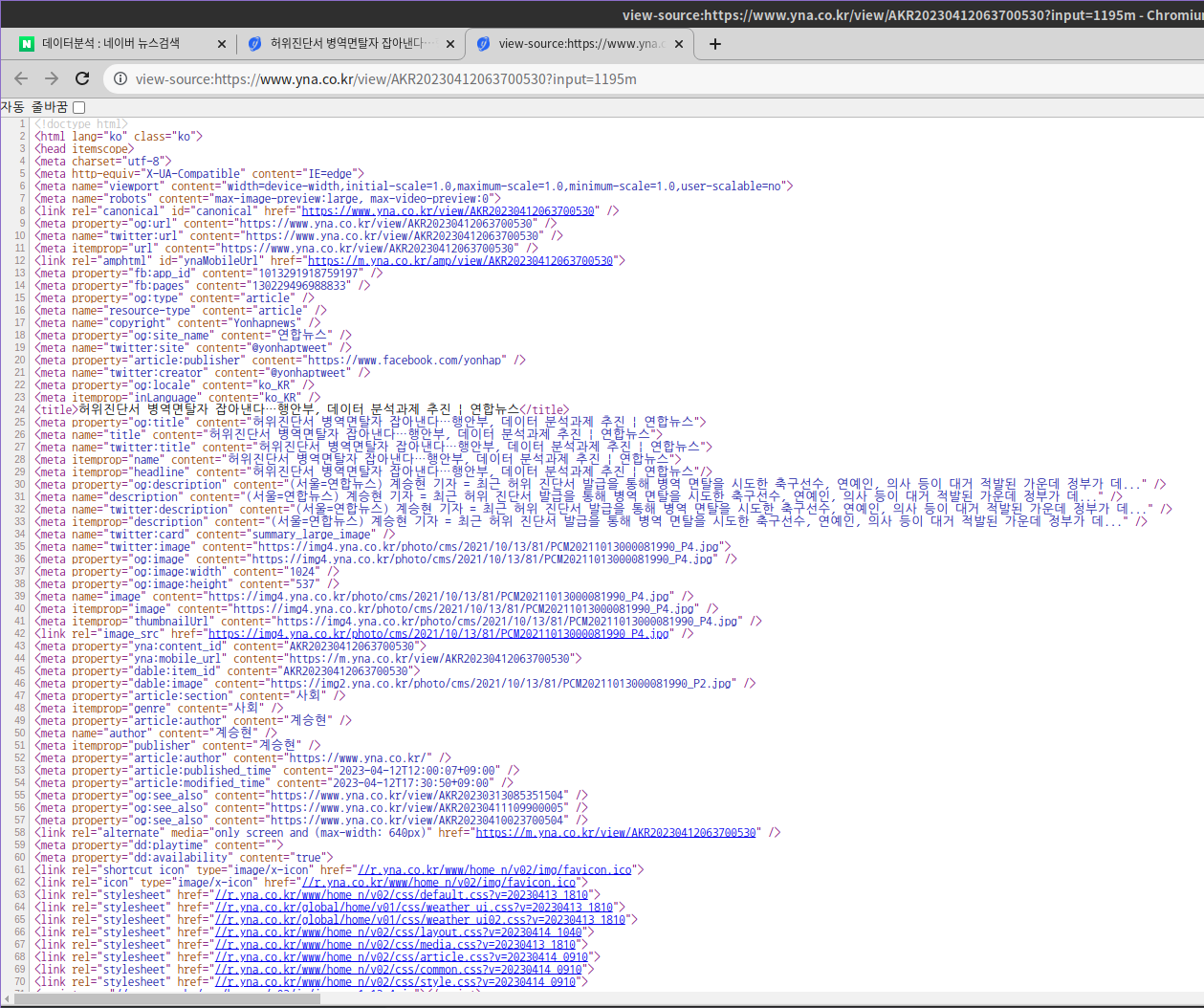
앞서 배운것처럼 <html>태그 안에 <head> 태그가 있고,
그 안에는 css나 JS와 관련된 여러 태그들로 구성되어 있는 것을 볼 수 있다.

잘 들여다보면 페이지의 박스와 관련된 div안에 div가 들어가 있는 식으로
여러 개의 div가 중첩되어 있는 것을 볼 수 있다.
만약 본문에 해당하는 태그를 찾으려면?
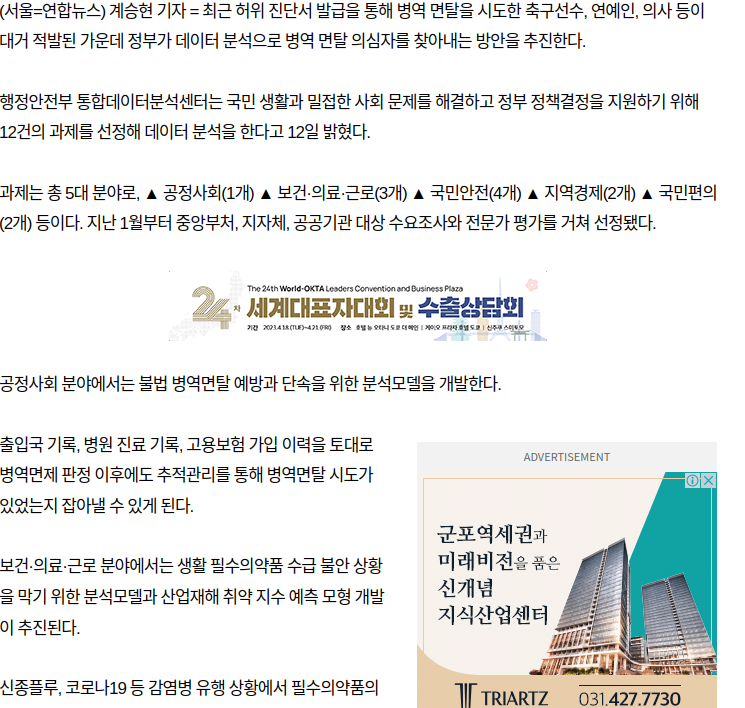
소스 페이지에서 본문에 해당하는 태그를 직접 찾으려면 매우 번거롭고, 오래 걸릴 것이다.
이때 우리를 도와줄 도구가 오늘 배울 개발자 도구 이다.
뉴스 기사 페이지에서 Ctrl + Shift + I를 누르면
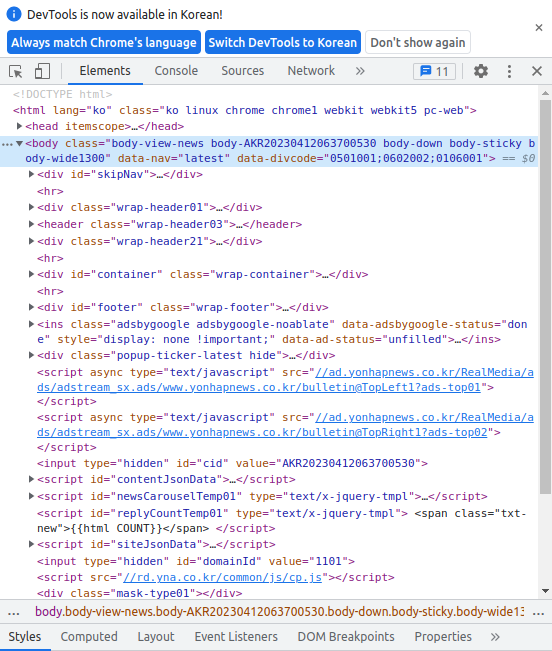
이런 친구가 나타난다.
여러 항목 중 Elements 항목은 페이지 소스와 똑같이 페이지의 HTML 태그를 보여준다.

이렇게 생긴 Inspector라는 녀석을 눌러주면
특정한 부분의 HTML 태그에 해당하는 줄로 이동하여 편하게 볼 수 있다.
Inspector를 이용하면 웹 스크래핑을 효율적으로 진행할 수 있다.

1. Webpage의 전체 HTML code를 가져온다.
2. 크롤링으로 원하는 부분의 태그를 찾는다. (Class & ID)
3. 해당 태그를 꺼낸 다음 태그를 제거하고 내부의 데이터만 뽑아낸다.
Web Scraping Process
웹 스크래핑은 다음과 같은 과정으로 진행된다.
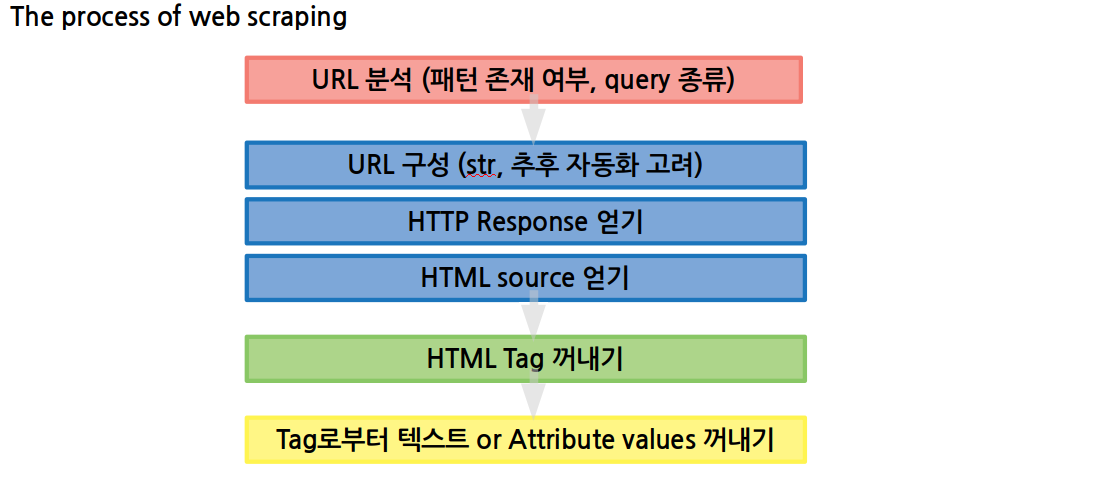
다음 수업부터 각 단계에 해당하는 내용들을 천천히 배워보자.
화이티잉
'나의 군 시절' 카테고리의 다른 글
| 나는 나랑 닮은 사람이 좋아. (0) | 2023.12.29 |
|---|---|
| Darknight 리뷰 Exploration & Visualization (2) | 2023.12.29 |
| Preprocessing Text Data (2) | 2023.12.27 |
| 텍스트 유사성 분석 (0) | 2023.12.19 |
| Web Scarping & HTML 기초 (2) | 2023.12.19 |