2023. 12. 29. 20:29ㆍPortfolio/kakao X goorm 군 장병 AI·SW 교육
가장 많이 등장하는 단어 추출해보기
앞서 배웠던 Tokenization과 Stopwords 제거를 이용하여
NLTK 라이브러리를 사용하여 영화 Dark Knight 리뷰에서 많이 등장하는 명사를 추출해보자!
1) Stopwords 준비
import nltk
from nltk.corpus import stopwords
from collections import Counter # 중복된 데이터가 저장된 배열에서 각 원소가 몇 번씩 나오는지 알기 위해 Counter import
stop_words = stopwords.words("english") # NLTK에서 제공하는 기본 영어 불용어 사전 추가
stop_words.append(',')
stop_words.append('.')
stop_words.append('’')
stop_words.append('”')
stop_words.append('—')
기존 NLTK 라이브러리에 포함되어 있는 stopwords 사전에 구두점(punctuation)을 추가하였다.
2) Text Data 준비
file = open('darkknight.txt', 'r', encoding="utf-8") # 읽기 형식으로 지정하고 인코딩은 'utf-8'로 설정
lines = file.readlines() # readlines 함수로 텍스트 파일의 내용을 읽어 리스트로 저장
darkknight 리뷰가 저장된 텍스트 파일을 읽기 형식으로 불러와 리스트에 저장했다.
이는 리스트 형식으로 저장함으로서 리뷰 각 줄을 tokenize 하기 위함이다.
3) Tokenizing
tokens = []
for line in lines: # for문을 통해 각 줄에 접근
tokenized = nltk.word_tokenize(line) # 각 줄을 tokenize
for token in tokenized:
if token.lower() not in stop_words:
tokens.append(token)
token이 저장될 리스트를 추가하고, Text data의 각 줄에 접근하여 각 줄을 tokenize를 진행하였다.
이때, token.lower()를 사용하여 token을 소문자로 변환하였는데,
이는 "Apple"과 "apple"처럼 대소문자를 구분하지 않고 동일한 단어로 취급하고 싶은 경우 사용한다.
소문자로 변환 이후 stop_words(불용어 사전)과의 대조를 통해 일치하지 않으면, token에 추가!
4) POS Tagging - 명사 종류만 모으기
tags = nltk.pos_tag(tokens) # tokenize한 결과를 품사 태깅
wordList = []
for word, tag in tags: # for문을 통해 각각의 (단어, 태그) 쌍에 접근
if tag in ['NN', 'NNS', 'NNP', 'NNPS']: # 만약 태그가 명사 종류이면:
WordList.append(word.lower()) # 소문자로 변환한 후 리스트에 첨부
counts = Counter(wordList) # 각 명사의 숫자를 센 결과를 변수에 저장(Counter -> {'home': 15, '단어':출현횟수, ...})
print(counts.most_common(10)) # 가장 많이 등장한 10개 명사를 출력[('movie', 406), ('batman', 303), ('film', 284), ('joker', 219), ('dark', 136), ('ledger', 131), ('knight', 124), ('time', 112), ('heath', 110), ('performance', 87)]
tokenize한 결과를 품사 태깅 후 많이 등장한 명사를 상위 10개만 출력한 결과
movie, batman, film, joker, ... 순으로 나타났다.
Dark Knight 리뷰에서 많이 등장하는 형용사 추출
리뷰에서 많이 등장한 명사를 추출한 결과로는 유의미한 인사이트를 도출하기에는 무리가 있다.
그렇다면 많이 등장한 형용사를 추출해서 앞서 추출한 명사와 연관지어 추측해보자!
# 1) Stopwords 준비하기
# 생략
# 2) Text data 준비하기
# 생략
# 3) Tokenizing
# 생략
# 4) POS tagging - 형용사 종류만 모으기
tags = nltk.pos_tag(tokens) # tokenize한 결과를 품사 태깅
for word, tag in rags: # for문을 통해 각각의 (단어, 태그)쌍에 접근
if tag in ['JJ', 'JJR', 'JS']: # 만약 태그가 형용사 종류이면:
wordList.append(word.lower()) # 소문자로 변환한 후 리스트에 첨부
counts = Counter(wordList) # 각 형용사의 숫자를 센 결과를 변수에 저장
print(counts.most_common(10)) # 가장 많이 등장한 10개 형용사를 출력
[('good', 141), ('great', 78), ('many', 54), ('much', 52), ('comic', 43), ('real', 29), ('bad', 28), ('little', 26), ('new', 25), ('last', 22)]
많이 등장한 형용사를 상위 10개만 출력한 결과
'good', 'great' 과 같은 긍정적인 단어가 가장 많이 등장했고, 영화의 요소를 알 수 있는 'comic', 'real',
'bad'와 같은 부정적인 단어도 확인할 수 있다.
나머지 많이 등장한 형용사와 앞서 추출해본 명사를 연관지어 영화 Dark knight 리뷰에 대한 인사이트를 도출해보면
1. 대부분의 사람들은 영화(movie) 자체 또는 배역(batman, joker)의 performance에 대해 긍정적으로 평가했다.
2. 소수의 사람들은 영화(movie) 자체 또는 배역(batman, joker)의 performance에 대해 부정적으로 평가했다.
(이때, 'new'와 'last'도 상위 10개에 포함된 것을 비추어 볼때 전작과 비교하여 리뷰를 했을 수 있다.)
token의 등장 횟수 시각화하기
이번에는 품사와 관계없이 리뷰에서 추출한 token의 등장 횟수를 그래프로 나타내보자
시각화를 통해 token의 등장 횟수를 파악해보면 품사별로 추출했을 때보다 훨씬 영화의 요소를 파악하기 쉬울 것이다.
시각화를 진행하기 전 먼저 '정규표현식'에 대해 알아보자
정규 표현식
"정규 표현식은 특정한 규칙을 가진 문자열의 패턴을 확인하는 데 사용하는 표현식(Expression)으로
텍스트에서 특정 문자열을 검색하거나 치환할 때 사용한다."
라고 하는데,, 감이 안 온다.
예를 들어, 전화번호부에서 번호를 검색하고 싶을 때,
해당 부분을 직접 리터럴로 검색하여 해당 부분을 검색한다.
import re # 파이썬에서 정규표현식을 사용하기 위해서는 Regex를 위한 모듈 re 모듈을 사용
text = "문의사항이 있으면 032-232-3245으로 연락주시기 바랍니다."
# 전화번호 패턴을 나타내는 정규표현식 컴파일
regex = re.compile(r'\d\d\d-\d\d\d-\d\d\d\d')
# 정규표현식과 매치되는 부분을 찾기
matchobj = regex.search(text)
# 매치된 전화번호를 가져와서 출력
phonenumber = matchobj.group()
print(phonenumber)
전화번호의 패턴이 032-232-3245와 같이 3자리-3자리-4자리로 구성되어 있다고 가정할때,
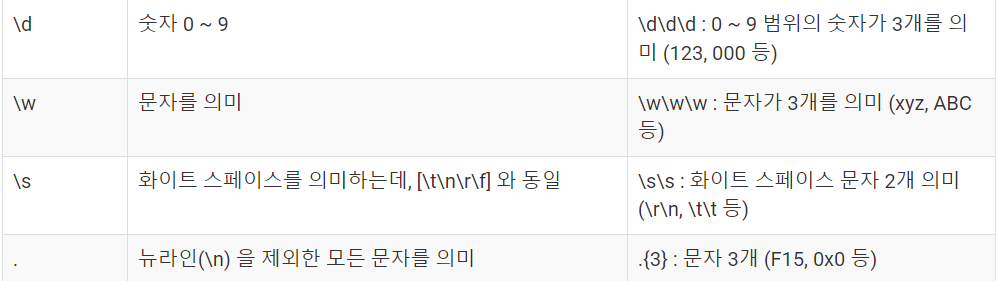
정규식에서 숫자를 의미하는 기호(리터럴) \d를 사용한다.
여기서 d는 digit을 의미하고 0~9까지의 숫자 중 아무 숫자나 될 수 있다.
다양한 정규식 패턴 표현
정규 표현식에는 \d말고도 다양한 문법과 기능들이 제공되는 패턴들이 있다.
다음은 자주 사용되는 패턴들이다.

이제 본론으로 돌아와서 리뷰에서 추출한 token의 등장 횟수를 그래프로 나타내보자
import matplotlib.pyplot as plt # 시각화를 위한 matplotlib를 사용하기 위해 임포트
import re # 정규표현식
stop_words = stopwords.words("english")
stop_words.append('else')
file = open('darkknight.txt', 'r', encoding="utf-8")
lines = file.readlines()
tokens = []
for line in lines:
tokenized = nltk.word_tokenize(line)
for token in tokenized: # 각 토큰이
if token.lower() not in stop_words: Stopwords # 리스트에 포함되어 있지 않으며,
if re.match('^[a-zA-Z]+', token): # 특수 기호에 해당하지 않을 경우,
tokens.append(token) # Token list에 추가
corpus = nltk.Text(tokens) # nltk의 Text 클래스를 이용하여 토큰들을 corpus로 만든다
plt.figure(figsize(10,3)) # 시각화 영역의 크기 설정
plt.title('Top 25 Words', fontsize=30) # 그래프 제목 설정
corpus.plot(25) # 25까지만 확인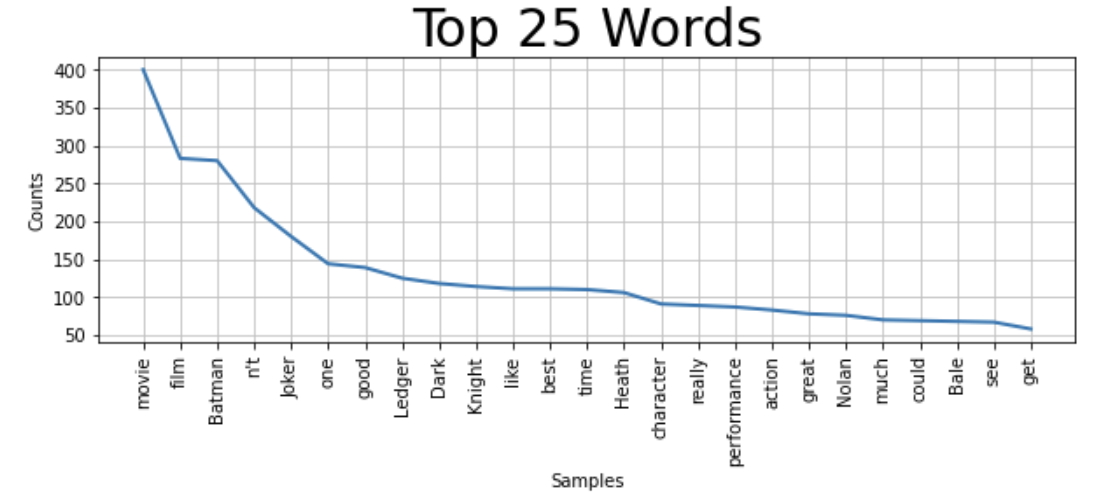
영화 리뷰의 토큰들을 시각화해보니 품사별로 추출했을 때와 비슷하게 나타난다.
그러나, n't와 같은 유의미하지 않은 토큰들도 추출된 것을 확인할 수 있다.
문맥 상 유사한 단어 출력하기
토큰의 등장횟수를 통해 리뷰의 문맥 상 유사한 단어도 출력해볼 수 있다.
file = open('darkknight.txt', 'r', encoding="utf-8")
lines = file.readlines()
tokens = []
for line in lines:
tokenized = nltk.word_tokenize(line)
for token in tokenized:
if token.lower() not in stop_words:
if re.match('^[a-zA-Z]+', token):
tokens.append(token)
corpus = nltk.Text(tokens)
print('Similar words : ')
corpus.similar('batman') # 유사한 단어들 (similar words)
Similar words : superhero film action movie character better iconic seen acting actor heath performance modern difficult villain second end good come best
리뷰에서 'batman'과 유사한 의미로 사용된 words의 결과를 통해
영화 리뷰 문맥에서 'batman'과 관련된 어떤 측면이나 주제를 나타낼 수 있다.
다음은 결과에 대한 해석 몇 가지 예시이다.
superhero film: 'batman'은 슈퍼히어로 영화의 일부로 간주될 수 있음
character: 'batman'은 특정 캐릭터를 가지고 있음
iconic: 'batman'은 아이코닉한 캐릭터
heath: 'heath'는 아마도 히스 레저(Heath Ledger)의 배우로서, 그의 특정 역할이나 연기와 관련
아마도 "Heath Ledger's performance as the Joker"와 같은 문맥에서 사용된 것으로 생각됨
villain: 'batman'이 등장하는 영화에서는 흔히 악당이 등장함
참고
'Portfolio > kakao X goorm 군 장병 AI·SW 교육' 카테고리의 다른 글
| 쇼생크 탈출과 갓파더 리뷰 텍스트 유사도 비교 (4) | 2024.01.01 |
|---|---|
| 나는 나랑 닮은 사람이 좋아. (0) | 2023.12.29 |
| Preprocessing Text Data (2) | 2023.12.27 |
| 텍스트 유사성 분석 (0) | 2023.12.19 |
| BeautifulSoup 맛 보기 (0) | 2023.12.19 |