2023. 12. 19. 14:13ㆍ나의 군 시절

Web Scraping vs Web Craling
우리는 원하는 정보를 얻기 위해 다양한 플랫폼을 이용하고 있다.
네이버와 같은 검색 포털부터, 야놀자와 같은 숙박업소 정보 플랫폼 등
카테고리 별로 떠오르는 플랫폼만 해도 수십 가지이다.
이처럼 수많은 플랫폼 사이에서 우리는
'우리가 찾는 데이터를 얼마나 많이 보유하고, 알맞게 보여주는지'에 따라 플랫폼을 선택한다.
플랫폼들은 수많은 데이터 속에서 웹 크롤링(Web Crawling) 과 웹 스크래핑(Scraping)
기술을 활용하여 고객에게 서비스를 제공한다.
두 기술의 차이가 뭘까?
웹 크롤링(Web Crawling)
웹 크롤링이란 웹 상의 정보들을 탐색하고 수집하는 작업이다.
인터넷에 존재하는 방대한 양의 정보를 사람이 일일이 파악하는 것은 불가능하므로,
규칙에 따라 자동으로 웹 문서를 탐색하는 웹 크롤러(Crawler)를 만들었다.
웹 크롤러가 하는 작업을 예를 들어 쉽게 설명하면,
네이버에 웹 크롤링을 검색해보자.
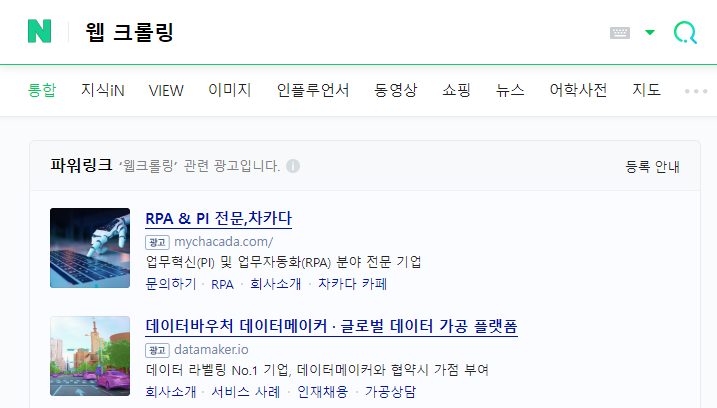
검색 결과 URL을 지닌 페이지 뿐 아니라 외부 사이트 링크도 요약본과 함께 노출되는 것을 확인할 수 있다.
이는 네이버 검색 엔진이 웹 크롤러가 수집한 데이터에
검색 알고리즘을 적용하여 정보를 추출해낸 결과이다.
이처럼 크롤러는 인터넷을 돌아다니며 여러 웹 사이트에 접속하고,
페이지의 내용과 링크의 복사본을 생성하여 다운로드 하고 요약본을 만든다.
그리고 검색 시 유용한 정보만을 노출하도록 검색 index를 붙인다.
웹 스크래핑(Web Scraping)
웹 스크래핑은 특정 웹 사이트나 페이지에서 필요한 데이터를 자동으로 추출해 내는 작업이다.
원하는 정보를 추출하기 위해 스크래퍼 봇 은 다음 과정을 거친다.
1. 특정 웹 사이트에 콘텐츠를 다운하기 위한 HTTP GET 요청
2. 웹 사이트가 OK하면 HTML 문서를 분석하여 특정 패턴의 데이터 추출
3. 추출된 데이터를 DB에 저장
웹 스크래핑은 자동으로 수집된 특정 정보가 필요한 분야에서 다양하게 활용되고 있다.
금융 및 시장의 경우, 스크래핑 기술을 활용하여 최신뉴스 정보를 모으기도 하고,
전자상거래 시장의 경우, 경쟁력 확보를 위해 경쟁사 상품의 정보를 수집하는 등에 활용되고 있다.
웹 크롤링과 웹 스크래핑의 장단점
심층 분석과 실시간 정보 제공에 유용한 웹 크롤링 (But 많은 리소스 요구)
웹 크롤링은 방대한 양의 정보를 수집하고, 크롤러는 정보 수집을 위해 계속해서 작동하므로
특정 키워드에 대한 '심층 분석'과 '변동성이 높은' 데이터를 분석할 때 유용하다.
하지만 방대한 데이터를 모으기 때문에 리소스가 많이 들어가는 단점이 있다.
정확한 정보를 요구할 때 쓰이는 웹 스크래핑 (But 데이터 양 한계)
웹 스크래핑은 특정 페이지에 대한 정보를 찾는데 집중하므로,
데이터 속 정확하고 확실한 정보를 적은 비용으로 수집하는데 유용하다.
이는 적은 리소스를 들이지만 그만큼 데이터의 한계가 있다는 것을 의미한다.
HTML
HTML(Hyper Text Markup Language)을 한 문장으로 설명하면 다음과 같다.
HTML = 웹 페이지의 뼈대
HTML은 웹 문서의 구조를 정의하고 표현하는 기본 마크업 언어로,
기본 구성요소는 태그(Tag) 이며 <> 를 사용하여 나타낸다.
태그는 일반적으로 시작과 끝을 표시하는 2개의 쌍으로 이루어져 있고,
종료태그 앞에 `/`를 붙여준다.
간단하게 만들어본 웹 페이지의 코드를 보자.
<html>
<head>
<title>TEST HTML</title>
<!-- 각종 웹페이지의 세팅과 관련된 코드들
외부의 CSS/JS 파일을 연결 <index.css>
외부의 이미지 파일을 바탕으로 favicon 세팅
Google analytics와 같은 도구를 위한 JS 코드 연결 -->
</head>
<body>
<div>
<!-- Division -->
</div>
<div>
<!-- Headline -->
<h2> 2번째로 큰 제목</h2>
<!-- Paragraph -->
<p><b>This</b> is the <span style="color:red";>first</span>paragraph</p>
<!-- Anchor (Hyperlink-Reference) -->
<a href="http://www.naver.com">네이버로 이동</a>
<!-- Image (Source) -->
<img src="https://upload.wikimedia.org/wikipedia/commons/thumb/c/c3/Python-logo-notext.svg/1869px-Python-logo-notext.svg.png" style="width:20%;">
<ol> <!-- Ordered-list -->
<li>First list item</li>
<li>Second list item</li>
<li>Third list item</li>
</ol>
<ul> <!-- Unordered-list -->
<li class="main-p" id="first-p">First list item</li>
<li class="main-p">Second list item</li>
<li>Thrid list item</li>
</ul>
</div>
</body>
</html>
주석은 <!-- comment --> 의 형식으로 사용하고,
태그 안에 다른 태그가 들어갈 수 있지만, 연 순서대로 닫아야 한다.
ID와 CLASS
<li class="main-p" id="first-p">First list item</li>
다음 태그를 보면,
li라는 Tag Name을 가지고 있고, class와 id라는 속성(Attribute)을 가지고 있고,
class와 id라는 Attribute 안에 main-p와 first-p라는 Value를 가지고 있다.
ID : 스타일을 지정할 때 한 가지만 지정해서 쓰는 이름이고,
여러 Tag가 동일한 ID를 가질 수는 없다.
CLASS : 그룹으로 묶어서 스타일을 지정할 때 쓰는 이름이고,
여러 Tag가 동일한 Class를 가질 수 있다.
[썸네일 사진 출처]
https://www.price2spy.com/blog/case-study-web-scraping-data-extraction-for-ecommerce/
'나의 군 시절' 카테고리의 다른 글
| 나는 나랑 닮은 사람이 좋아. (0) | 2023.12.29 |
|---|---|
| Darknight 리뷰 Exploration & Visualization (2) | 2023.12.29 |
| Preprocessing Text Data (2) | 2023.12.27 |
| 텍스트 유사성 분석 (0) | 2023.12.19 |
| 개발자 도구 & Web Scraping 프로세스 (0) | 2023.12.19 |