2024. 1. 1. 22:14ㆍ나의 군 시절
앞서 배운 TF-IDF 개념과 코사인 유사도 개념을 가지고
명작 쇼생크 탈출과 갓파더 리뷰 텍스트간 유사도를 계산해보자
TF-IDF & 코사인 유사도를 이용하여 텍스트 간 유사도 계산하기
1) 유사도 분석에 필요한 패키지 불러오기
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity2) 영화 리뷰 파일 불러오기
# 쇼생크 탈출 리뷰 텍스트 불러오기
file open('shawshank.txt', 'r', encoding='utf-8')
lines = file.readlines() # 영화 리뷰 파일의 모든 라인을 읽어와 리스트로 저장
doc1 = ' '.join(lines)
# doc1 = '' # 리뷰 데이터를 담기 위한 String 변수 생성
# for line in lines: # for문을 통해 lines에 있는 모든 텍스트를 doc1에 이어 붙임
# doc1 += line
# 갓파더 리뷰 텍스트 불러오기
file = open('godfather.txt', 'r', encoding = 'utf-8')
lines = file.readlines() # 영화 리뷰 파일의 모든 라인을 읽어와 리스트로 저장
doc2 = ' '.join(lines)
3) 리뷰 텍스트 파일 벡터화
corpus = [doc1, doc2] # doc1, doc2를 합쳐 corpus list를 생성
vectorizer = TfidfVectorizer() # TfidfVectorizer() 객체 변수 생성
# fit_transform()를 통해 corpus의 텍스트 데이터를 벡터화해 X에 저장하고 dense한 matrix로 변환
X = vectorizer.fit_transform(corpus).todense()
쇼생크 탈출과 갓파더 리뷰 텍스트 문서를 합쳐 corpus 리스트를 생성하고,
이 문서 집합을 TF-IDF 값으로 변환해주기 위해 vectorizer 객체를 생성하였다.
fit_transform 메서드는 corpus의 텍스트 데이터를 TF-IDF로 벡터화하고, 이를 행렬 'X'에 저장한다.
todense() 메서드는 모델 학습이나 예측을 수행하기 위해 희소 행렬(Sparse Matrix)을 밀집 행렬(Dense Matrix)로 변환한다.
.todense()의 역할
기본적으로 fit_transform의 결과로 만들어지는 행렬은 희소행렬(Sparse matrix)이다.
희소행렬 내에는 무수히 많은 '0'이 존재하는데 이러한 '0'이라는 값을 저장하는 것 역시 메모리를 차지하므로,
'0'인 값들은 아예 제외하고 나머지 숫자들만 실제로 저장하는 방식으로 처리한다.
이렇게 저장된 데이터로부터 얻어내야 하는 것은 값이 모두 채워진 행렬(Dense matrix)이므로,
마지막에 .todense() 함수를 실행 시 Sparse matrix 로부터 2행 3276열 크기의 Dense Matrix를 만들어 돌려받을 수 있다.
print(X)
print(type(X)
print(X.shpae) # 각 행은 각 영화 리뷰 데이터의 word(열) 출현 빈도에 대한 dense matrix
[[0.0071001 0.00332632 0. ... 0. 0.00166316 0. ]
[0.00889703 0. 0.00138938 ... 0.00138938 0. 0.00138938]]
<class 'numpy.matrix'>
(2, 3276)
쇼생크 탈출과 갓파더의 코사인 유사도 확인
위에서 구한 dense matrix를 이용하여 두 영화의 코사인 유사도를 확인해보자
print("Similarity between 'The Shawshank Redemption' and 'The Godfather': ", cosine_similarity(X[0], X[1]))
Similarity between 'The Shawshank Redemption' and 'The Godfather': [[0.9437827]]
코사인 유사도가 상당히 높은 수치로 나온 것을 토대로
두 영화를 보고나서 작성한 리뷰의 내용이 상당히 유사한 것을 확인할 수 있었다.
여러 영화 리뷰 텍스트 간 유사도 계산하기
우리는 두 개의 영화 리뷰 텍스트 간 유사도를 확인하는 법을 배웠다.
그럼 여러 개의 영화 리뷰 유사도를 확인할 수 있을까?
같은 방법을 사용해서 3개의 영화 리뷰를 비교해보자
file = open('shawshank.txt', 'r', encoding = 'utf-8')
lines = file.readlines()
doc1 = ' '.join(lines)
file = open('godfather.txt', 'r', encoding = 'utf-8')
lines = file.readlines()
doc2 = ' '.join(lines)
file = open('inception.txt', 'r', encoding = 'utf-8')
lines = file.readlines()
doc3 = ' '.join(lines)
corpus = [doc1, doc2, doc3] # doc1, doc2, doc3를 합쳐 corpus list를 생성
vectorizer = TfidfVectorizer() # TfidfVectorizer() 변수 생성
# fit_transform()를 통해 corpus의 텍스트 데이터를 벡터화해 X에 저장하고 X를 dense한 matrix로 변환
X = vectorizer.fit_transform(corpus).todense()
# 영화 간 cosine similarity 계산
print("Similarity between 'The Shawshank Redemption' and 'The Godfather': ", cosine_similarity(X[0], X[1]))
print("Similarity between 'The Shawshank Redemption' and 'Inception': ", cosine_similarity(X[0], X[2]))
print("Similarity between 'The Godfather' and 'Inception': ", cosine_similarity(X[1], X[2]))Similarity between 'The Shawshank Redemption' and 'The Godfather': [[0.93484399]]
Similarity between 'The Shawshank Redemption' and 'Inception': [[0.18080469]]
Similarity between 'The Godfather' and 'Inception': [[0.16267018]]
3개의 영화 리뷰 텍스트 간 유사성을 비교해보니 쇼생크 탈출-갓파더 영화 리뷰를 제외하고,
텍스트 유사성이 현저히 떨어지는 것을 알 수 있었다.
각 행 vs 전체 행 코사인 유사성 계산 & 시각화
pandas 라이브러리를 이용하여 DataFrame으로 행렬을 표현하면
훨씬 효과적으로 코사인 유사성을 확인할 수 있다.
result = pd.DataFrame(cosine_similarity(X, X))
result.columns = ['Shawshank', 'Godfather', 'Inception']
result.index = ['Shawshank', 'Godfather', 'Inception']
print(result)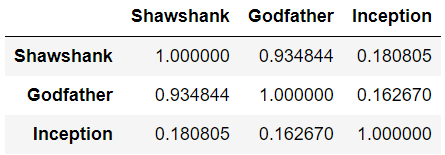
이번에는 DataFrame을 히트맵으로 시각화 해보자!
import seaborn as sns
import matplotlib.pyplot as plt
plt.figure(figsize=(10,10))
sns.heatmap(result, annot=True, fmt='f', linewidths=5, cmap='RdYlBu')
sns.set(font_scale=1.5)
plt.tick_params(top=True, bottom=False, labeltop=True, labelbottom=False) # 가로축 라벨이 맨 위에 나타나야 함
plt.show()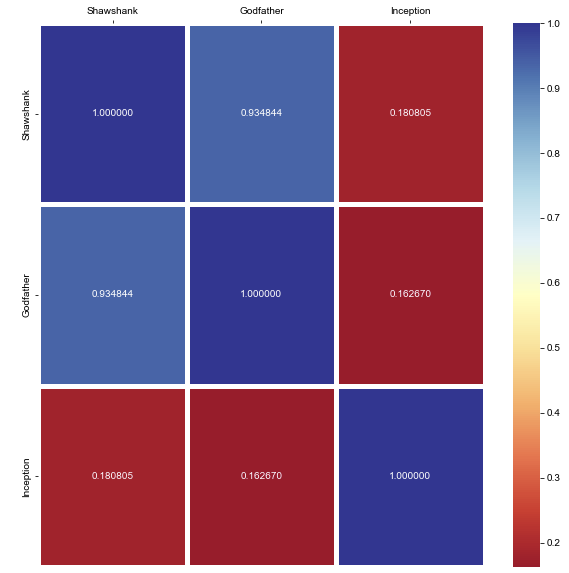
히트맵으로 시각화하니 유사성이 높을수록 파랑 계열색 낮을수록 빨강 계열색으로 훨씬 비교가 용이하다.
'나의 군 시절' 카테고리의 다른 글
| '뉴진스' 네이버 뉴스 기사 크롤링 (2) | 2024.01.02 |
|---|---|
| 나는 나랑 닮은 사람이 좋아. (0) | 2023.12.29 |
| Darknight 리뷰 Exploration & Visualization (2) | 2023.12.29 |
| Preprocessing Text Data (2) | 2023.12.27 |
| 텍스트 유사성 분석 (0) | 2023.12.19 |