2025. 1. 31. 22:56ㆍ이것저것
AI의 발전은 이제 더 이상 새로운 이야기가 아니다.
그러나, 그 발전이 가져오는 윤리적 문제는 충분히 논의되고 있는가?
AI 모델이 점점 더 정교해지고 우리 삶의 중요한 결정에 관여하게 되면서,
AI를 활용하는 개발자는 기술적 성취뿐만 아니라 윤리적 책임도 함께 고민해야 하는 시대가 되었다.

우리는 정말 AI를 신뢰할 수 있을까?
이 글에서는 LG Aimers 6th에서 다룬 AI 윤리 개념 강의를 바탕으로,
이 질문에 대한 답을 고민해보고자 한다.
✔️ 신뢰할 수 있는 AI를 위한 필수 요소
1.1 명확한 데이터 해석: 상관관계와 인과관계를 혼동하고 있지는 않은가?
AI 모델이 높은 정확도를 보인다고 해서 그것이 반드시 인과관계를 증명하는 것은 아니다.
이는 데이터 분석에서 흔히 발생하는 오류 중 하나로,
두 변수 간의 상관관계가 있다고 해서 한 변수가
다른 변수의 직접적인 원인이 된다고 단정짓는 실수를 의미한다.
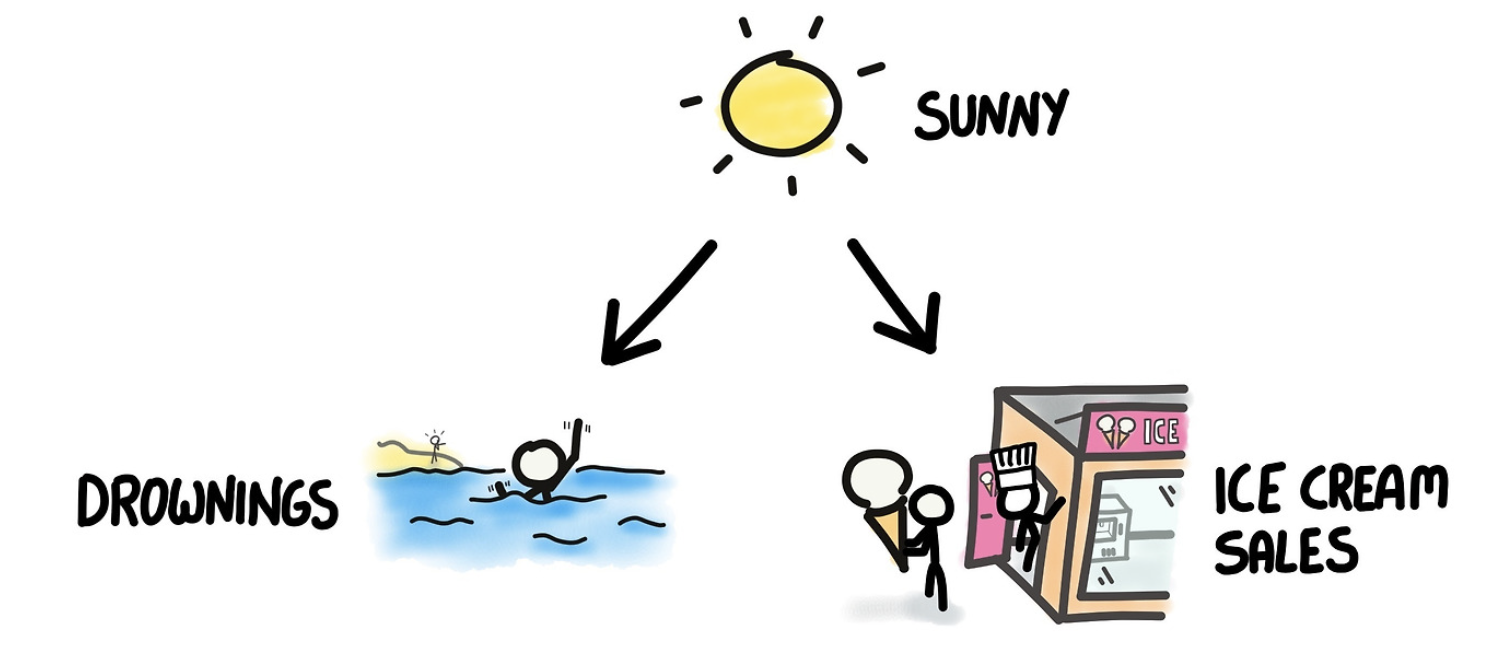
예를 들어, 여름철이 되면 아이스크림 판매량과 익사 사고가 동시에 증가하는 경향이 있다.
그러나 이는 더운 날씨라는 공통 요인이 작용한 결과일 뿐,
아이스크림을 먹는 것이 익사의 원인이 되는 것은 아니다.
이러한 착오를 피하지 않으면 잘못된 의사결정을 내릴 가능성이 커지며,
특히 의료, 금융, 정책 결정과 같은 분야에서는 심각한 결과를 초래할 수 있다.
Harvard University의 Judea Pearl 교수는 그의 저서 The Book of Why에서 다음을 강조하며,
"단순한 상관관계 분석만으로는 인과적 추론을 할 수 없다"
인과관계를 입증하기 위해서는 보다 정교한 분석 기법이 필요함을 역설했다.
또한, 데이터 과학에서 "Spurious Correlation(허위 상관)"이라는 개념이 존재하는데,
실제로는 아무런 인과관계가 없음에도 불구하고 두 변수가 우연히 높은 상관을 보이는 현상을 의미한다.
해결책
1️⃣ A/B 테스트 및 무작위 대조 실험(Randomized Controlled Trial) 활용
A/B 테스트는 웹사이트 디자인, 광고 효과, 의료 처방과 같은 분야에서 널리 사용되는 기법으로,
한 변수를 조작하고 다른 변수를 고정한 상태에서 결과를 비교하는 방식이다.
RCT는 실험 그룹과 대조군을 무작위로 배정하여 인과관계를 검증하는 방법으로,
의학 연구에서 신약의 효과를 검증할 때 필수적으로 활용된다.
2️⃣ 도구적 변수(Instrumental Variable) 기법 적용
어떤 변수가 인과적 영향을 미치는지 직접 관찰할 수 없을 때,
제3의 변수를 도구적 변수로 활용하여 분석하는 방법이다.
3️⃣ 데이터의 맥락을 고려한 해석
단순한 통계적 수치에 의존하지 말고, 데이터가 수집된 배경과 도메인 지식을 함께 고려해야 한다.
특정 변수가 연관성을 보이는 이유를 논리적으로 설명할 수 있는지 검토하고
필요하다면 추가적인 실험을 설계해야 한다.
5️⃣ Counterfactual Analysis(반사실 분석) 적용
특정 사건이 발생하지 않았을 경우의 시나리오를 가정하여, 해당 변수의 인과적 영향을 분석하는 방법이다.
예를 들어, 어떤 마케팅 캠페인이 매출 증가에 영향을 미쳤는지 확인하기 위해,
캠페인이 없었던 경우의 매출을 예측하고 비교하는 방식으로 활용된다.
즉, 인과관계를 입증하기 위해서는 단순한 상관관계를 넘어서 실험적 접근과 정교한 분석 기법이 필요하다.
AI 모델이 단순한 상관관계를 학습하는 것을 방지하기 위해,
데이터 과학자는 항상 "왜?"라는 질문을 던지고, 체계적인 검증 과정을 거쳐야 한다.
1.2 데이터 품질 관리: 전처리 과정이 신뢰성을 결정한다
AI 모델의 성능은 학습 데이터의 품질에 크게 좌우된다. 만약 데이터가 부정확하거나 편향되어 있다면,
모델 또한 왜곡된 결정을 내릴 가능성이 높아진다.
특히, 잘못된 데이터가 포함된 상태에서 학습이 진행될 경우
모델이 현실과 동떨어진 패턴을 학습하거나 특정 그룹에 대한 차별적 결과를 초래할 수 있다.
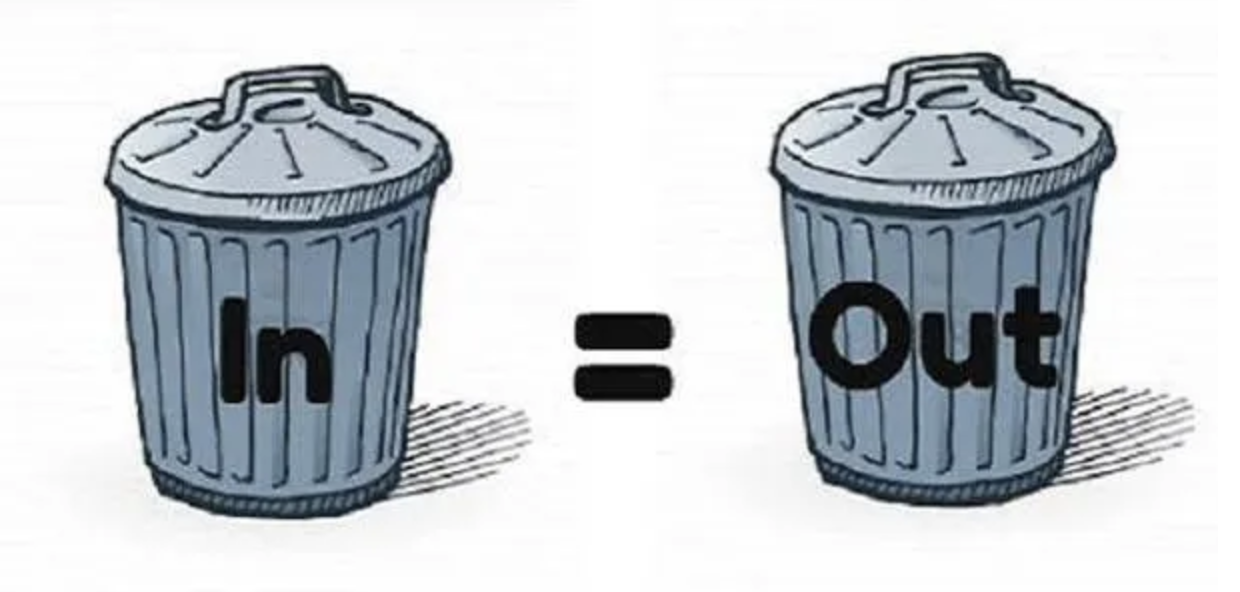
"Garbage In, Garbage Out(GIGO)"
데이터 품질이 낮으면 최적의 알고리즘을 사용하더라도 올바른 결과를 기대하기 어렵다.
예시로, Amazon의 AI 기반 채용 시스템이 남성 지원자를 우대하는 편향적 결정을 내렸던 사건이 있다.
이는 과거 10년 동안의 채용 데이터에서 남성이 더 많이 채용된 사실을 학습했기 때문이다.
데이터 자체의 편향은 모델의 결과의 편향으로 이어지고, 이는 기업의 의사결정에 악영향을 미칠 수 있다.
데이터 품질을 높이는 방법
1️⃣ Error bar 추가: 모델 예측값의 불확실성을 시각적으로 표현
모델의 예측값이 절대적인 진리가 아님을 나타내기 위해 신뢰구간(Confidence Interval) 또는
크레디블 인터벌(Credible Interval, Bayesian Statistics)을 활용해야 한다.
의료 AI 모델이 암 진단 확률을 제공할 때 단순히 "80% 확률로 암입니다"라고 제시하는 것보다,
"80% ± 5%"처럼 불확실성을 함께 표현하면 신뢰도를 높일 수 있다.
이 기법은 금융 및 리스크 분석에서도 활용되며, 특정 주식의 예상 수익률을 단순 수치가 아닌
범위로 제시하면 투자자가 보다 신중한 결정을 내릴 수 있다.
2️⃣ 적합한 통계 검정 활용: 데이터 분포를 고려한 신뢰성 검증
데이터가 정규분포를 따르는지 여부에 따라 검정 방법을 적절히 선택해야 한다.
- 정규분포를 가정하는 경우: t-test, ANOVA를 사용하여 그룹 간 차이를 검정할 수 있다.
- 정규성을 따르지 않는 경우: Mann-Whitney U 검정, Kruskal-Wallis 검정을 활용할 수 있다.
- 범주형 데이터 검정: 카이제곱 검정을 통해 변수 간 독립성을 분석할 수 있다.
이러한 검정 절차를 거치면 데이터가 신뢰할 수 있는지, 특정 패턴이 우연이 아닌지 검증할 수 있다.
3️⃣ Outlier 제거: 데이터 왜곡 방지
이상치는 모델의 학습을 방해하고 예측 성능 저하로 이어지므로,
이를 감지하고 처리하는 것이 매우 중요하다.
- Z-score 표준화: 특정 값이 평균에서 얼마나 벗어나 있는지를 측정하여 이상치를 탐색한다.
- IQR 방법: 사분위수(Q1, Q3)를 이용해 이상치를 감지하고 제거한다.
- LOF(Local Outlier Factor): 데이터 밀도를 기반으로 이상치를 감지하는 기법
4️⃣ Normalization & Standardization: 모델의 안정적인 학습 보장
데이터 스케일 차이가 클 경우 특정 feature가 모델 학습에서 과도하게 영향을 미칠 수 있으므로,
이를 방지하기 위해 데이터 표준화가 필요하다.
- Min-Max Scaling: 데이터를 0과 1 사이로 변환하여 상대적 크기를 유지하는 방법
- Z-score Normalization(Standardization): 평균이 0, 표준편차가 1이 되도록 변환하는 방법
5️⃣ EDA: 데이터 신뢰도 향상
데이터의 특성을 충분히 이해하는 과정이 선행되지 않으면 분석 결과를 신뢰할 수 없다.
- 기술통계 분석: 평균, 중앙값, 분산, 표준편차 등을 확인하여 데이터의 전반적인 구조를 파악한다.
- 시각화 기법 활용: Box Plot, Scatter Plot을 활용하여 이상치나 패턴을 직관적으로 탐색한다.
- Feature Correlation 분석: 상관 행렬을 통해 변수 간 관계를 파악하여 다중공선성 문제를 점검
결론적으로, 데이터 품질이 낮다면 아무리 정교한 AI 모델도 신뢰할 수 없는 결과를 도출할 수밖에 없다.
따라서 데이터 전처리 과정에서 이상치 제거, 데이터 표준화, 통계적 검증 등을 철저히 수행해야 하며,
모델이 예측한 결과에 대한 불확실성을 명확히 표현하는 것이 중요하다.
높은 품질의 데이터를 바탕으로 AI 모델을 구축해야만 신뢰할 수 있는 결과를 얻을 수 있으며,
이는 궁극적으로 비즈니스 의사결정의 정확성을 높이는 핵심 요소가 된다.
1.3 데이터 양과 편향: 충분한 데이터 없이 AI를 신뢰할 수 있을까?
AI 모델의 일반화 성능은 학습 데이터의 양과 질에 의해 결정된다.
데이터가 부족하면 모델은 단순한 패턴만 학습하게 되어 실제 환경에서 신뢰할 수 없는 결과를 낼 가능성이 높다. 특히, 학습 데이터가 특정 그룹이나 환경에 치우쳐 있다면 모델의 예측이 특정 조건에서만 유효하고,
새로운 상황에서는 성능이 크게 저하될 수 있다.
대표적인 사례로 2016년 Microsoft의 AI 챗봇 'Tay'가 있다.
Tay는 인터넷 사용자들의 데이터를 학습하면서 특정 편향적이고 극단적인 표현을 빠르게 습득했고,
결국 출시 하루 만에 서비스가 중단되었다.
이 사건은 AI 모델이 훈련 데이터의 영향을 얼마나 직접적으로 받는지를 보여주는 사례다.
데이터 양과 편향을 줄이기 위한 전략
1️⃣ 충분한 학습 데이터 확보: 데이터 증강과 외부 데이터 활용
데이터 증강 기법을 활용하여 데이터 부족 문제를 완화할 수 있다.
- 이미지 데이터의 경우: 회전, 크롭, 색상 변환 등의 기법을 적용하여 데이터를 다양하게 확장한다.
- 텍스트 데이터의 경우: 동의어 치환, 문장 순서 변경 등을 활용한다.
2️⃣ 데이터 편향 방지: 다양한 출처의 데이터 활용 및 균형 잡힌 샘플링
데이터 편향을 줄이기 위해서는 다양한 출처 Source에서 데이터를 수집하는 것이 중요하며,
특정 그룹이 과소 대표되거나 과대 대표되지 않도록 층화 샘플링 기법을 적용해야 한다.
리샘플링(Resampling)
- 언더샘플링: 데이터가 많은 그룹에서 일부 샘플을 제거하여 균형을 맞춘다.
- 오버샘플링: 데이터가 적은 그룹의 샘플을 증가시켜 모델이 편향되지 않도록 한다.
- SMOTE: 적은 클래스의 데이터를 인위적으로 생성하여 균형을 맞춘다.
결론적으로, AI 모델을 신뢰하기 위해서는 충분한 데이터 확보뿐만 아니라,
데이터 편향을 적극적으로 탐지하고 수정하는 과정이 필수적이다.
단순히 대량의 데이터를 확보하는 것만으로는 충분하지 않으며,
데이터 출처의 다양성, 균형 잡힌 샘플링 등의 접근법을 결합해야 한다.
이를 통해 AI 모델이 보다 포괄적이고 신뢰할 수 있는 결정을 내릴 수 있도록 해야 한다.
1.4 Black Box 문제: AI가 왜 그런 결정을 내렸는가?
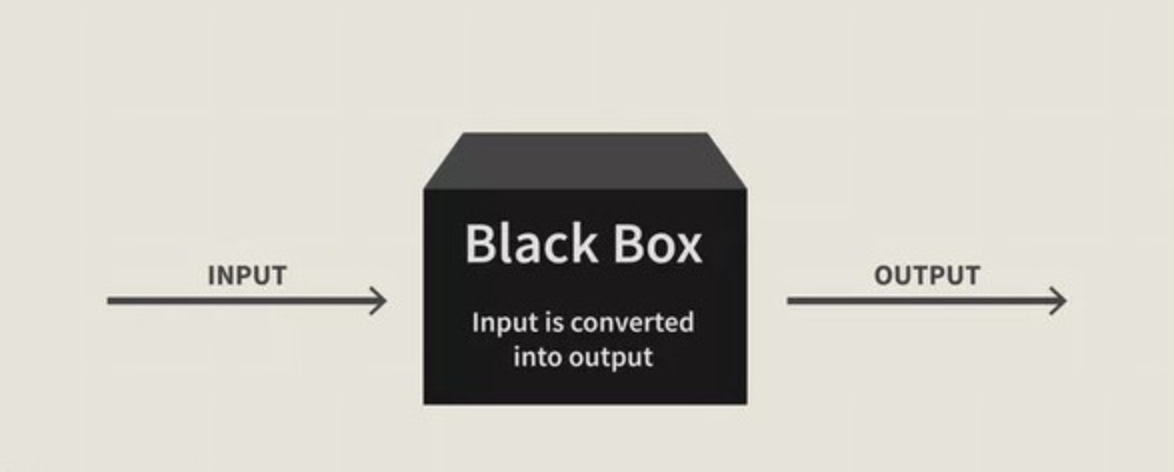
AI 모델의 예측 과정이 불투명하면 신뢰도를 확보하기 어렵다.
특히, 의료, 금융, 채용과 같이 중요한 의사결정을 내리는 AI라면 투명성과 해석 가능성이 필수적이다.
하지만 복잡한 딥러닝 모델은 수많은 뉴런과 가중치를 활용하여 결정을 내리므로,
사람이 직관적으로 이해하기 어렵다.
대표적인 사례로 2018년 미국에서 도입된 AI 기반 채용 시스템이 있다.
이 시스템은 이력서를 분석하여 지원자의 적합성을 평가했지만,
훈련 데이터의 편향으로 인해 여성 지원자를 낮게 평가하는 문제가 발생했다.
AI가 왜 특정 결정을 내렸는지 설명할 수 없었기 때문에, 해당 시스템은 결국 폐기되었다.
AI의 Black Box 문제 해결을 위한 접근법
1️⃣ 모델의 민감도 평가: 특정 변수의 영향력 분석
Feature Importance Analysis(특성 중요도 분석)
랜덤 포레스트, XGBoost와 같은 트리 기반 모델은 특성 중요도를 기본적으로 제공하며,
이를 통해 어떤 변수가 결정에 가장 큰 영향을 미치는지 확인할 수 있다.
예를 들어, 의료 AI에서 ‘나이’와 ‘혈압’ 중 어떤 변수가 심장병 예측에 더 중요한지를 분석할 수 있다.
Partial Dependence Plot(PDP) 및 Individual Conditional Expectation(ICE)
PDP는 특정 변수가 증가하거나 감소할 때 모델의 예측이 어떻게 변하는지를 시각적으로 보여준다.
ICE는 개별 데이터 포인트에 대한 영향을 분석하여 개인별 맞춤 해석이 가능하도록 한다.
2️⃣ 규칙 기반 모델과 신경망 모델을 조합하여 투명성 강화
Hybrid Models(하이브리드 모델)
신경망 모델의 복잡성을 유지하면서도, 규칙 기반 모델을 함께 사용하여 설명력을 높일 수 있다.
예를 들어, 금융 도메인에서는 신경망을 활용한 예측 모델을 사용하되,
최종 의사결정에는 명확한 규칙(예: 신용 점수 기준)을 적용하는 방식이 효과적이다.
Symbolic AI + Machine Learning
심볼릭 AI는 사람이 이해할 수 있는 논리적 규칙을 제공하는 반면,
머신러닝은 패턴 인식을 통해 예측력을 강화한다.
두 가지를 결합하면 예측력과 설명 가능성을 모두 확보할 수 있다.
결론적으로, AI의 Black Box 문제를 해결하지 않으면, 사용자는 AI를 신뢰하기 어렵고,
의료·금융·채용 등의 분야에서 AI 의사결정의 정당성을 확보하기 어렵다.
이를 해결하기 위해 변수의 중요도를 분석하며, 하이브리드 모델을 적용하는 방식이 필요하다.
또한, AI의 윤리적 책임을 강화하고, 투명성을 높이기 위한 법·정책적 노력이 병행되어야 한다.
1.5 웹 데이터 활용의 윤리적 고려: 우리가 보는 데이터는 정말 객관적인가?
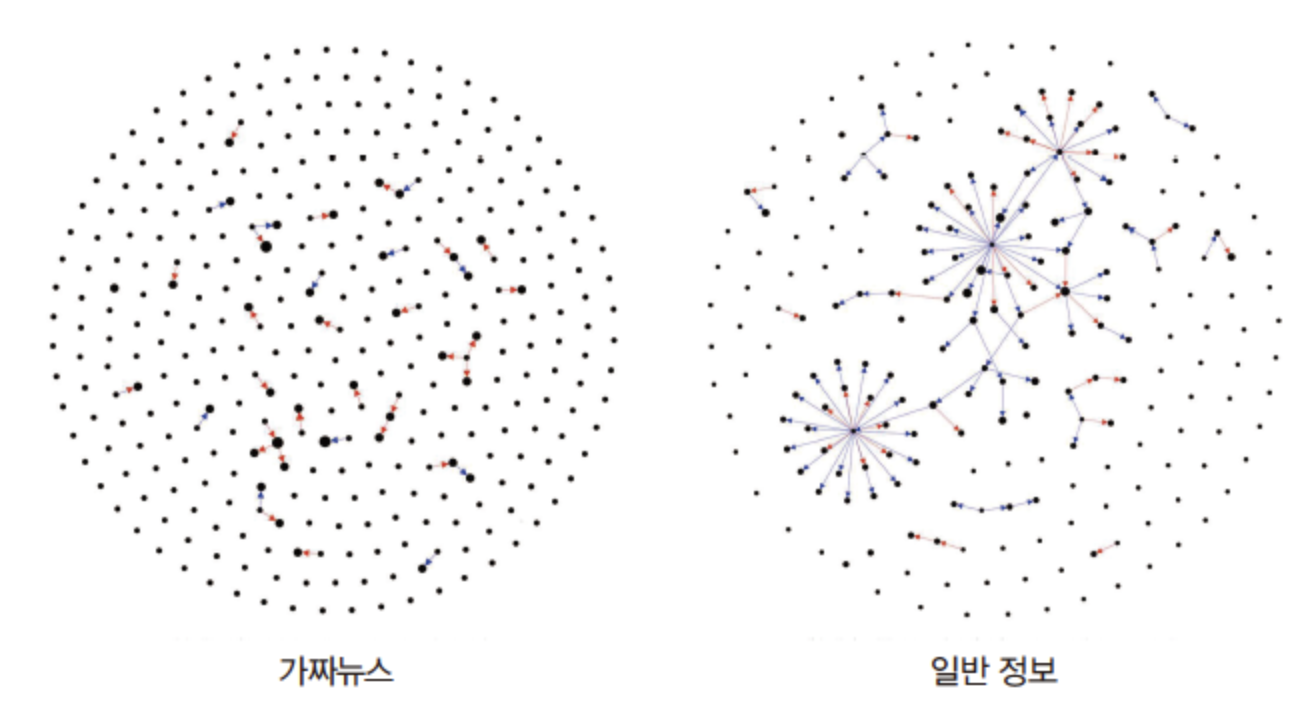
인터넷에서 수집한 데이터는 AI 모델의 학습에 중요한 역할을 하지만,
모든 데이터가 객관적이고 신뢰할 수 있는 것은 아니다.
오히려 웹 데이터는 Bias, 가짜 뉴스, Filter Bubble 등의 영향을 받아 왜곡될 가능성이 크다.
따라서 AI가 웹 데이터를 활용할 때는 윤리적 고려가 필수적이다.
대표적인 사례로 소셜 미디어의 극단화 현상이 있다.
예를 들어, 트위터나 페이스북의 추천 알고리즘은 용자 관심사에 맞춰 콘텐츠를 노출하기 때문에,
특정 의견이 강화되고 반대 의견은 점점 배제될 수 있다.
이러한 환경에서는 잘못된 정보가 빠르게 확산될 위험이 크며,
AI 모델이 이를 학습할 경우 편향된 결론을 도출할 수 있다.
침묵의 나선(Spiral of Silence)과 데이터 왜곡
침묵의 나선 이론은 사람들이 다수 의견에 동조하려는 경향을 설명한다.
이론에 따르면 소수 의견을 가진 사람들은 사회적 압박을 느끼고 발언을 자제하는 경향이 있으며,
이에 따라 특정 의견이 과대대표될 수 있다.
예를 들어, 정치적 이슈나 논쟁적인 주제에서는 다수 의견이
더욱 강하게 보이지만, 실제로는 반대 의견도 존재할 가능성이 크다.
소셜 미디어에서의 데이터 편향은 감정적으로 강한 콘텐츠(예: 분노, 공포를 자극하는 글)는
더욱 빠르게 공유되며, 중립적인 정보는 상대적으로 가려질 가능성이 크다.
신뢰할 수 있는 웹 데이터 활용을 위한 접근법
1️⃣ 데이터 수집 시 출처 검증: 신뢰도 높은 데이터만 활용
정부 기관, 학술 연구, 공신력 있는 뉴스 사이트에서 제공하는 데이터를 우선적으로 활용한다.
뉴스 신뢰도를 평가하는 프로젝트(예: Fact Check)를 참고하여 데이터 출처를 선정한다.
2️⃣ AI 모델의 편향을 줄이기 위한 데이터 다변화
특정 그룹의 의견이 과대대표되지 않도록 다양한 출처의 데이터셋을 수집해야 한다.
또한, Random Sampling 기법을 적용하여 특정 패턴이 과도하게 반영되지 않도록 한다.
특정 주제에 대해 찬반 양측의 데이터를 균형 있게 반영하는 것이 중요하다.
결론적으로, 웹 데이터는 방대한 양을 제공하지만, 모든 데이터가 객관적이고 신뢰할 수 있는 것은 아니다.
따라서, 신뢰할 수 있는 출처에서 데이터를 수집하고, 데이터 다양성을 확보하는 것이 필수적이다.
AI가 보다 공정하고 신뢰할 수 있는 분석을 수행하려면,
단순히 데이터의 양만이 아니라 데이터의 질과 균형이 중요하다는 점을 항상 고려해야 한다.
데이터 사이언티스트의 마음가짐
데이터에 대한 깊은 관심과 지속적인 학습
좋은 데이터사이언티스트는 단순한 기술자가 아니라, 데이터 자체에 대한 깊은 호기심을 가지고 지속적으로 배우고 성장하는 사람이다. 데이터의 출처와 품질을 면밀히 검토하고, 상관관계와 인과관계를 혼동하지 않으며, 신뢰할 수 있는 분석과 해석을 수행하는 것이 핵심이다. 데이터의 투명성을 높이고, AI 모델이 신뢰할 수 있는 결정을 내릴 수 있도록 끊임없이 고민하자.
도전적인 목표 설정과 윤리적 책임
데이터사이언티스트는 단순히 모델의 성능을 높이는 것이 아니라, 윤리적이고 공정한 AI를 개발하는 것을 목표로 삼아야 한다. 데이터 편향을 최소화하고, 알고리즘의 투명성을 높이며, AI가 사람들에게 실질적인 가치를 제공할 수 있도록 노력해야 한다. 50%의 성공 확률을 가지는 도전적인 목표를 설정하고, 실패를 두려워하지 않으며 끊임없이 연구하고 학습하는 자세를 유지하자.
데이터의 힘을 긍정적으로 활용하기
데이터는 올바르게 활용하면 사회를 변화시키는 강력한 도구가 될 수 있다. 그러나 잘못된 데이터 해석이나 편향된 알고리즘은 오히려 부정적인 영향을 미칠 수도 있다. 데이터사이언티스트로서 객관적인 분석, 공정한 데이터 처리, 데이터가 긍정적인 방향으로 활용될 수 있도록 책임을 다하기 위해 노력하자.
'이것저것' 카테고리의 다른 글
| [Git/Github] Git 필수 명령어 (1) (0) | 2025.08.10 |
|---|---|
| [Git/Github] 미루던 Git 배우기 시작 (4) | 2025.08.10 |