2025. 8. 4. 23:19ㆍData Analysis/Computer Science
이런 말을 한 번쯤 들어봤을 것이다.
“메모리가 부족해”
여기서 말하는 메모리가 무엇인지,
그리고 우리 컴퓨터 성능을 결정하는 중요한 요소인 CPU와 메모리가 어떻게 상호작용하는 지 알아보자.
컴퓨터의 가장 중요한 부품인 CPU는 컴퓨터의 두뇌 역할을 한다.
이때, 직접 데이터를 저장하거나 프로그램을 실행하는 것이 아니라,
‘메모리’ 라는 공간에 올라와 있는 프로그램의 명령어를 읽어와서 실행하는 역할을 한다.
그렇다면, 메모리는 무엇인가?
메모리는 컴퓨터가 현재 실행 중인 프로그램과 데이터를 임시로 저장하는 공간이다.
우리가 사용하는 워드, Notion 등 모든 프로그램은 실행되기 위해 반드시 메모리에 올라와야 한다.
하지만, 모든 메모리가 같은 종류는 아니고,
다양한 종류의 메모리를 효율적으로 사용하기 위해 ‘메모리 계층’ 이라는 구조를 가지고 있다.
속도와 용량의 딜레마, 메모리 계층

레지스터 (CPU 내부 메모리):
휘발성, 속도 가장 빠름, 기억 용량이 가작 적다. CPU가 즉시 처리해야 하는 데이터를 저장한다.
캐시 (L1, L2 캐시):
레지스터보다는 느리지만 RAM보다는 훨씬 빠르다.
자주 사용될 데이터를 임시로 저장하여 CPU가 RAM까지 가지 않도록 돕는다.
주기억장치 (RAM):
캐시보다 느리지만 보조기억장치보다 훨씬 빠르다.
현재 실행 중인 프로그램과 데이터를 저장한다.
전원이 꺼지면 내용이 사라지는 휘발성 메모리이다.
보조기억장치 (HDD, SSD):
가장 느리지만, 가장 용량이 크고 저렴하다.
또한, 비휘발성 메모리이기 때문에, OS, 프로그램 파일 등이 이곳에 저장된다.
이러한 계층 구조는 다음과 같은 중요한 원칙을 가진다.
계층 위로 올라갈수록 (보조기억장치 → RAM → 캐시 → 레지스터)
- Cost 증가
- Capacity 감소
- Speed 증가
이 구조의 핵심은 속도 차이에서 발생하는 병목 현상을 해결하기 위함이다.
CPU는 초고속으로 데이터를 처리하지만, 보조기억장치는 매우 느리다.
만약, CPU가 매번 HDD에서 데이터를 직접 가져온다면,
CPU는 대부분의 시간을 기다리는 데 낭비할 것이다.
이를 해결하기 위해 중간에 속도가 다른 여러 메모리를 두어 효율을 극대화 하는 것이다.
캐시(Cache)의 등장: 속도 차이를 극복하는 영리한 전략
특히 Cache는 이러한 속도 차이를 해결하기 위한 핵심적인 역할을 한다.
CPU와 RAM 사이의 속도 차이가 너무 크기 때문에,
자주 사용될 것 같은 데이터를 미리 RAM에서 캐시로 복사해 놓는다.
이렇게 하면 CPU는 느린 RAM까지 가지 않고, 가까이에 있는 빠른 캐시에서 데이터를 바로 가져올 수 있다.
캐시의 존재 이유는 다음과 같다.
“자주 사용하는 데이터를 미리 가까운 곳에 두어 속도 차이로 인한 병목 현상을 줄이자”
그렇다면 캐시는 어떤 데이터를 ‘자주 사용될 것’이라고 판단할 수 있을까?
바로 ‘지역성의 원리(Locality of reference)’라는 과학적 근거를 바탕으로 한다.
지역성의 원리
프로그램은 일반적으로 다음과 같은 특성을 보인다.
시간 지역성
최근 사용된 데이터는 가까운 미래에 다시 사용될 가능성이 높다는 특성
반복문 안에서 변수 i는 계속해서 반복적으로 사용되는데,
let arr = Array.from({length:10}, ()=> 0);
console.log(arr)
for (let i=0; i<10; i+=1) {
arr[i] = i;
}
console.log(arr)
캐시는 이 변수를 계속 캐시에 두어 CPU가 빠르게 접근하도록 한다.
공간 지역성
최근에 접근한 데이터의 주변에 있는 데이터들도 가까운 미래에 사용될 가능성이 높다는 특성이다.
즉, 배열 arr[i]에 연속적으로 접근할 때, arr[0], arr[1] 등 캐시는 주변의 값까지 함께 가져온다.
이러한 원리를 통해 캐시는 어떤 데이터를 저장할지 결정하고, CPU의 성능을 최대로 끌어올린다.
캐시를 제대로 사용하는 방법: 캐시 히트와 캐시 미스
캐시를 사용하면서 발생하는 두 가지 중요한 상황이 존재한다.

캐시 히트 (Cache Hit)
CPU가 필요한 데이터가 캐시에 이미 존재하는 경우
→ CPU는 캐시에서 데이터를 바로 가져오므로 매우 빠른 속도로 작업을 처리할 수 있다.
캐시 미스 (Cache Miss)
CPU가 필요한 데이터가 캐시에 없는 경우
CPU는 어쩔 수 없이 느린 RAM으로 가서 데이터를 찾아와야 한다.
이때, RAM에서 가져온 데이터를 캐시에 저장해 두어 다음번에는 빠르게 접근할 수 있도록 한다.
캐시 매핑 (Cache Mapping)
CPU는 RAM에서 캐시로 데이터를 옮길 때, 어떤 주소에 저장해야 할지 규칙을 정해야 한다. → 캐시 매핑
| 이름 | 설명 | 장점 | 단점 |
| Direct Mapping | 주메모리의 특정 주소를 캐시의 정해진 한 곳에만 저장하는 방식 | 구조가 간단하고 처리 속도가 빠름 | 여러 메모리 블록이 같은 캐시 공간을 사용하면 충돌이 자주 발생 |
| Associative Mapping | 주메모리에서 가져온 데이터를 캐시의 어떤 공간에도 자유롭게 저장하는 방식 | 충돌 발생 가능성이 적음 | 캐시의 모든 블록을 탐색해야 하므로 속도가 느림 |
| Set-Associative Mapping | Direct Mapping과 Associative Mapping의 장점을 합친 방식 | 충돌 가능성이 낮으면서도 탐색 속도를 개선 | 구조가 가장 복잡함 |
운영체제 밖, 소프트웨어의 캐시
웹 브라우저의 캐시
우리가 웹 서핑을 할 때, 브라우저는 웹 서버로부터 받은 데이터를
쿠키, 로컬 스토리지, 세션 스토리지 등에 저장한다. 이들이 바로 소프트웨어 적인 캐시이다.
쿠키 (Cookie)
만료기한이 있는 작은 저장소이다. 사용자 로그인 정보나 개인 맞춤 설정 등을 저장한다.
로컬 스토리지 (Local Storage)
만료기한이 없어 웹 브라우저를 닫아도 유지되며, 탭을 닫으면 데이터가 삭제된다.
세션 스토리지 (Session Storage)
탭 단위로 데이터가 유지되며, 탭을 닫을 때 해당 데이터가 삭제된다.
이러한 웹 브라우저의 캐시 덕분에 웹사이트에 다시 방문했을 때 더 빠른 속도로 페이지를 볼 수 있다.
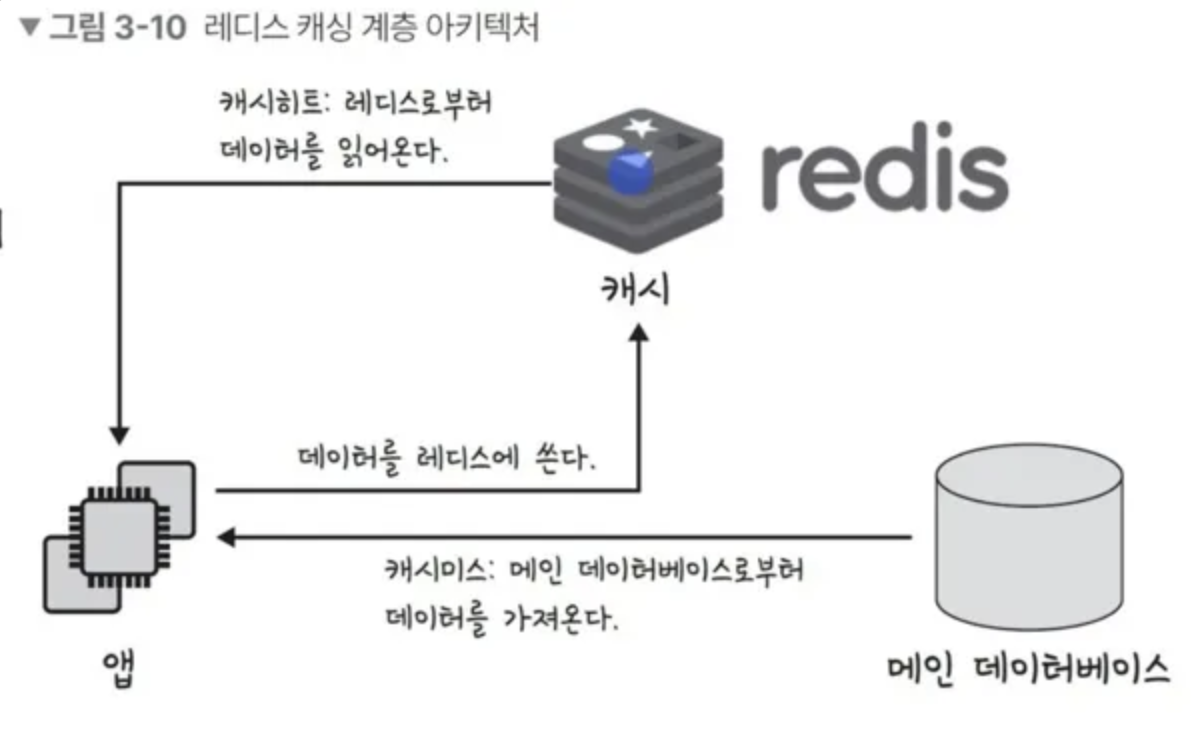
데이터베이스의 캐싱 계층
대규모 웹 서비스를 구축할 때, DB의 부하를 줄이기 위해
메인 DB 앞에 Redis와 같은 ‘캐싱 계층’ 두는 경우가 많다.
자주 요청되는 데이터를 캐싱 계층에 저장해두면,
매번 느린 메인 DB에 접근하지 않고도 빠르게 데이터를 응답할 수 있어 서비스의 성능을 크게 향상시킬 수 있다.
마치며
메모리 계층, 특히 캐시의 개념은 단순히 하드웨어의 이야기가 아니다.
“자주 쓰는 것을 가까이에 두자”는 단순하면서도 강력한 원리가
컴퓨터 시스템 전체에 걸쳐 성능을 최적화하는 핵심적인 아이디어이다.
'Data Analysis > Computer Science' 카테고리의 다른 글
| 프로세스와 스레드 (3) | 2025.08.11 |
|---|---|
| 메모리 관리 (3) | 2025.08.05 |
| 운영체제와 컴퓨터 (4) | 2025.08.01 |
| 자료구조는 왜 중요할까? (0) | 2025.03.14 |
| 추상 자료형 (Abstract Data Type) (0) | 2024.07.04 |