2025. 8. 3. 23:06ㆍTools & Skills/SQL
많은 엔지니어 및 프로그래머는 공통적으로 문제를 해결할 때 반복문을 사용하는 것에 익숙해져 있다.
→ 복잡한 문제를 작고 개별적인 단위(레코드)로 나눈 다음, 그 단위에 반복문을 적용해 해결하는 사고방식이다.
“문제가 생기면 일단 분할하고 보자”, “상향 식으로 접근하자”, “모듈을 작게 나누자”의 프로그래밍 철학
이러한 반복문 의존증을 SQL 및 RDB의 패러다임 관점에서 이야기 해보자.
SQL 및 RDB의 패러다임
SQL에는 본질적으로 반복문이 없다.
이는 SQL은 처음부터 반복문이 없는 것이 더 좋다는 철학을 바탕으로 설계됐기 때문인데,
이로 인해 사용자에게 편리함을 제공한다.
SQL은 기본적으로 집합(Set) 기반의 언어이고,
개발자가 개별 레코드를 어떻게 처리할지 명시적으로 반복문을 작성할 필요 없이,
원하는 결과 집합의 조건만 선언하면 DBMS가 내부적으로 최적화된 방식으로 처리한다.
*이러한 사고방식의 차이가 ‘반복문 의존증’과 충돌하는 지점이다.
그럼 반복문 의존증이 SQL과 만나면 무슨 문제점이 있을까?
1.1 반복문 의존증이 SQL과 만나는 문제점
1. 온라인 처리:
화면에 몇 개의 레코드를 출력하고자 SELECT문을 반복문 안에 넣어
레코드 하나씩 접근하는 것은 SQL의 집합 기반 철학에 맞지 않다.
SELECT * FROM ... WHERE ...
즉, 한 번에 집합을 가져오는 것이 효율적이다.
2. 배치 처리:
대량의 데이터를 처리할 때, SQL이 아닌 호스트 언어(Java, C++)의 반복문을 사용하여
레코드 하나씩 가져와 처리하고 테이블을 갱신하는 것은 집합 연산을 활용하지 못해 비효율적이다.
그렇다면, 반복문 의존증의 현실적인 원인은 무엇일까?
1.2 반복문 의존증의 현실적인 원인
1. SQL을 적용하기 힘든 작업:
모든 문제가 SQL의 집합 연산으로 쉽게 해결되는 것은 아니며,
복잡한 절차적 로직이 필요한 경우, 호스트 언어 반복문이 더 합리적일 수 있기 때문이다.
2. 프레임워크의 제약:
미들웨어, ORM(Object-Relational Mapper) 같은 프레임워크는
내부적으로 반복문 코드를 사용하여 RDB에 접근하는 경우가 많다.
이로 인해, 개발자는 의도치 않게 반복문 기반의 사고방식에 종속될 수 있다.
이제, 호스트 언어(C, JAVA)와 선언형 프로그래밍(SQL)의 차이를 알아보자.
1.3 선언형(Declarative) vs 명령형(Imperative) 프로그래밍
1. 명령형:
C, Java 같은 언어는 for, while 루프 등을 사용하여
“어떻게(How)” 문제를 해결할지 단계별로 명령한다. → ‘반복문 의존증의 근간’
2. 선언형:
SQL은 “무엇을(What)” 원하는지 선언한다.
-- "30세 초과인 모든 사용자를 원한다"고 선언, 처음부터 끝까지 반복 X
SELECT * FROM users WHERE age > 30
패러다임의 충돌
익숙한 명령형 패러다임(반복문)을 SQL이라는 선언형 패러다임에 억지로 적용하려 할 때,
비효율성과 성능 저하가 발생할 수 있다.
개발자는 문제의 성격에 따라 가장 적합한 패러다임을 선택하고,
각 패러다임의 장점을 최대한 활용하는 사고방식을 가져야 한다.
SQL의 강점은 집합 연산이고, 이는 하나의 쿼리로 대량의 데이터를 효율적으로 처리하는 것이다.
즉, 레코드 단위로 접근하는 것은 SQL의 장점을 버리는 행위가 될 수 있다.
현실적인 절충
SQL로 집합을 가져오고, 호스트 언어의 반복문을 사용하여
각 레코드에 복잡한 비지니스 로직을 적용하는 하이브리드 방식이 일반적이다.
SQL이 효율적인 부분(집합 처리)과 호스트 언어(복잡한 절차적 로직)을
명확히 구분하고 적절히 사용하는 것이 중요하다.
반복계의 공포
반복계 해답의 가장 ‘좋은 점’은 ‘SQL 처리를 단순화 할 수 있다’는 것이다.
2.1 반복계의 단점
같은 기능을 구현한다고 가정할 때,
반복계로 구현한 코드는 포장계로 구현한 코드에 성능적으로 이길 수가 없다.
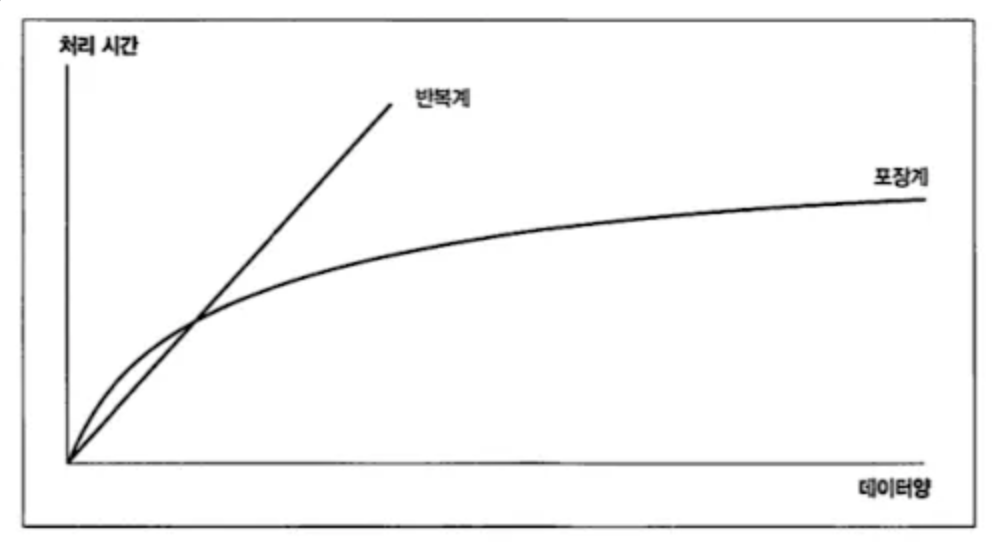
처리하는 레코드 수가 많아지면 많아질수록 차이는 점점 더 벌어진다.
반복계의 처리 시간이 처리 대상 레코드 수에 대해 선형으로 증가하는 이유는
<처리 횟수> * <한 회에 걸리는 처리 시간>
한 회에 걸리는 시간이 일정하다고 가정하면 처리 횟수(=처리 대상 레코드 수)에 비례할 것이기 때문이다.
또한, 반복계는 호스트 언어의 반복문을 사용하여 SQL 쿼리를 실행하는 방식으로,
for (record in list) { UPDATE table SET ... WHERE id = record.id;}
1. 리소스 분산 비효율:

반복문 1회당 실행되는 SQL 구문은 매우 단순하여, 처리할 데이터 양이 적다.
따라서 CPU 멀티코어 또는 RAID 디스크의 I/O 병렬화 이점 활용 어렵다는 한계가 있다.
또한, 전체 작업은 직렬적으로 실행되므로, 분산 처리를 통한 성능 향상이 어렵다.
2. DBMS 진화 혜택 제한:
DBMS의 옵티마이저와 아키텍쳐는 ‘대규모 데이터를 다루는 복잡한 SQL 구문’을 빠르게 처리하도록 진화하고 있다.
그러나, 반복계에서 사용되는 단순한 SQL은 최신 DBMS 기능 혜택을 크게 받지 못한다.
결과적으로 반복계는 성능 튜닝의 가능성이 낮고, 느린 성능을 개선하려면 대대적인 App 코드 수정이 필요하다.
2.2 SQL 실행의 오버 헤드
SQL을 실행은 단순히 데이터 처리뿐만 아니라, 여러 부수적인 과정(전처리 및 후처리)을 포함한다.
전처리 단계:
1. SQL 구문을 네트워크로 전송
애플리케이션 서버(App)에서 DB 서버로 SQL 쿼리 전송
2. 데이터베이스 연결
DB 서버가 해당 SQL을 처리할 세션을 설정
→ DB 연결 및 세션 설정 오버헤드는 커넥션 풀(Connection Pool) 기술을 통해 미리 연결을 확보함으로써 크게 감소시킬 수 있다.
3. SQL 구문 파싱
DB 서버가 받은 SQL 구문의 문법을 분석하고 의미를 해석
→ DBMS마다 방식이 다르고 복잡해 최대 1초까지 소요될 수 있다.
4. SQL 구문의 실행 계획 생성 또는 평가
파싱된 SQL을 어떻게 실행할지 가장 효율적인 방법을 결정
→ 파싱은 SQL을 받을 때마다 매번 실행되므로,
작은 SQL을 반복적으로 실행하는 경우(반복계) 오버헤드가 누적되어 전체 성능 저하를 초래한다.
후처리 단계:
5. 결과 집합을 네트워크로 전송:
DB 서버가 처리 결과를 App서버로 보낸다.
오버헤드에 대한 분석:
1과 5 (네트워크 전송):
App과 DB가 같은 물리적 서버에 있으면 발생하지 않지만, 분리된 환경에서는 오버헤드가 발생한다.
보통 같은 데이터센터 내 고속 LAN에 있으므로 오버헤드가 딱히 일어나지 않는다.
2.3 시사점 및 중요한 교훈
1. SQL 성능은 데이터 처리 자체만으로 결정되지 않는다:
SQL의 WHERE 절 조건이나 인덱스 사용 여부에만 집중하는 것이 아닌,
실제로 SQL이 실행되기 전 후의 과정에서도 많은 시간이 소요될 수 있다.
특히, 네트워크 전송이나 DB 연결 오버헤드가 미미하더라도,
SQL 파싱과 실행 계획 수립은 무시할 수 없는 오버헤드라는 점을 인식해야 한다.
2. SQL 파싱의 비용:
SQL 파싱은 쿼리의 복잡성, DBMS에 따라 큰 비용이 발생할 수 있다.
만약, 동일한 쿼리를 반복해서 실행하는 경우,
DB는 매번 쿼리를 다시 파싱하고 실행 계획을 수립해야 한다.
3. ‘반복문 의존증’과 SQL 오버헤드의 연결고리:
“작은 SQL을 여러 번 반복하는 반복계”는 바로 반복문 의존증에 기반한 코딩 패턴이다.
‘여러 번’에 해당하는 SQL 파싱 오버헤드를 발생시키고,
‘여러 번’의 실행 계획을 수립하게 된다.
이는 SQL 파싱 오버헤드(데이터를 처리하기 위해 파싱하는 과정에서
발생하는 불필요한 비용이나 자원 소모)를 발생시키고,
작업 속도가 현저히 느려질 수 있다는 점을 명심하자.
4. 성능 최적화 방안:
작은 SQL을 반복하기 보다는,
UPDATE ... WHERE id IN (...)과 같이 하나의 쿼리로 대량의 데이터를 처리하는 것이
SQL 파싱 및 실행 계획 수립 오버헤드를 한 번만 발생시켜 훨씬 효율적이다.
이외에도 Prepared Statement와 같이
동일한 구조의 쿼리를 반복해서 실행하는 경우,
쿼리를 미리 컴파일(파싱 및 실행 계획 수립)하여,
바인딩 변수만 바꾸어 재사용하는 기술도 존재한다.
→ SQL 파싱 오버헤드를 줄이는 매우 효과적인 방법이다.
반복계의 장점
반복계가 비효율적임에도 불구하고 여전히 사용되는 이유는, 다음과 같다.
1. 실행 계획의 안정성:
반복계에서 사용되는 쿼리는 WHERE 절에 PK를 사용하는 등 매우 단순하다.
이 때문에 DB의 옵티마이저는 항상 unique scan 또는 index range scan과 같은
단순하고 예측가능한 실행 계획을 수립한다.
변동이 일어나도 옵티마이저에서 사용하는 인덱스를 바꾸는 정도기 때문에,
비용 기반 옵티마이저에서는 숙명적인 것이고, 그로부터 조금은 자유로워질 수 있는 것이다.
이는 실행 계획이 안정적이라는 것은 성능 변동 위험이 적다는 의미이기도 한데,
특히 SQL 구문 내부에서 결합을 사용하지 않아도 된다는 것이 굉장히 크게 작용한다.
→ 실행 계획 변동에서 가장 골칫거리는 바로 JOIN 알고리즘의 변경
2. 예상 처리 시간의 정밀도:
실행 계획이 단순하고 성능이 안정적이라는 것은
예상 처리 시간의 정밀도가 높다는 장점을 가졌다는 말과 같다.
<처리 시간> = <한 번의 실행 시간> * <실행 횟수>
간단한 공식으로 전체 작업 시간을 정확히 예측할 수 있는데,
단순한 쿼리의 한 번의 실행 시간이 안정적이기 때문에 전체 처리 시간 예측의 정밀도가 높다.
3. 세밀한 트랜잭션 제어:
반복문 내에서 특정 횟수마다 COMMIT을 수행하는 등 트랜잭션을 세밀하게 제어할 수 있다.
오류가 발생하더라도 마지막 COMMIT 지점부터 다시 처리를 시작할 수 있어 복구(Recovery)가 용이하다.
'Tools & Skills > SQL' 카테고리의 다른 글
| 트러블슈팅: MySQL 대용량 CSV 파일 LOAD DATA로 넣기 (2) | 2025.08.11 |
|---|---|
| 절차 지향에서 선언형으로 (3) | 2025.08.01 |
| 신규 가입자의 2주차 재방문율 감소 문제 (4) | 2025.07.22 |
| [SQL] 프로그래머스 Lv.4 보호소에서 중성화한 동물 (0) | 2025.04.05 |
| [SQL] LeetCode #511 - Game Play Analysis (0) | 2025.03.19 |