2025. 3. 19. 20:11ㆍTools & Skills/SQL
SQL 문제 풀이 - 첫 로그인 날짜 찾기
단순 SQLD 시험 응시를 넘어 앞으로 꾸준하게 SQL을 공부해보려고 합니다.
그 과정 중 난이도와 상관 없이 1문제라도 꾸준하게 "분석적으로" 풀이해볼 생각입니다. 많관부
문제 설명
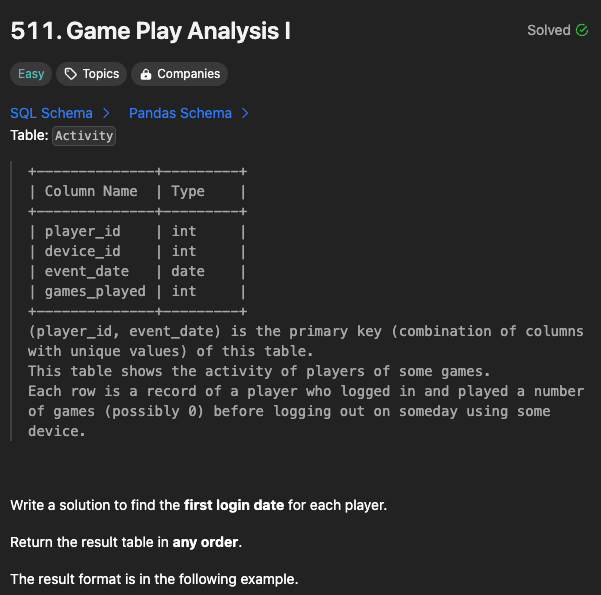
(player_id, event_date) is the primary key (combination of columns with unique values) of this table. This table shows the activity of players of some games. Each row is a record of a player who logged in and played a number of games (possibly 0) before logging out on someday using some device.
Write a solution to find the first login date for each player.
Return the result table in any order.
The result format is in the following example.
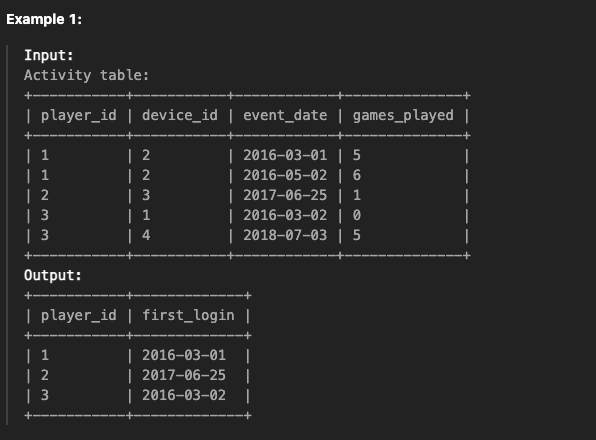
이 문제는 각 player_id에 대해 가장 빠른 event_date를 찾는 문제입니다.
즉, 각 플레이어가 처음 로그인한 날짜를 구하는 것이 핵심입니다.
처음 작성한 풀이
처음에는 문제를 잘못 이해하여 플레이어가 게임을 처음 진행한 날짜를 찾는다고 착각했고,
다음과 같은 엉망진창 쿼리를 작성했습니다.
SELECT DISTINCT(player_id), event_date
FROM Activity
WHERE games_played = 1;
여기서 games_played = 1 조건을 포함했는데,
사실 문제에서 요구하는 것은 "게임을 했는지 여부와 관계없이" 첫 로그인 날짜를 찾는 것입니다.
✅ 즉, games_played 조건 없이, player_id별 event_date의 최소값을 구해야 합니다.
올바른 풀이 접근법
그렇다면 어떤 사고 방식으로 접근해야 했을까요?
올바른 알고리즘은 다음과 같습니다.
1. 각 플레이어의 첫 로그인 날짜를 찾아야 하므로 player_id 별로 그룹화(GROUP BY)
2. 각 그룹에서 가장 빠른(MIN) 날짜 선택
이를 SQL 쿼리로 작성하면?
-- 해당 플레이어가 기록한 가장 빠른 로그인 날짜를 찾고,
SELECT player_id, MIN(event_date) AS first_login -- 결과 컬럼명을 문제에서 요구한 대로 변경
FROM Activity
GROUP BY player_id; -- 각 플레이어별로 그룹 형성
위 쿼리는 각 플레이어별로 가장 빠른 로그인 날짜를 정확하게 찾아줍니다.
(참고: AS first_login을 사용해 결과 컬럼명을 문제에서 요구하는 형식으로 변경했습니다.)
확장
단순히 기본적인 풀이를 이해하는 것을 넘어 다른 접근법은 없을까? 고민해봤습니다.
만약 GROUP BY 없이 해결하려면?
ORDER BY를 활용하여 정렬한 뒤, 고유한 값을 반환하는 ROW_NUMBER()를 사용할 수도 있습니다.
WITH Ranked AS (
SELECT player_id, event_date,
ROW_NUMBER() OVER (PARTITION BY player_id ORDER BY event_date ASC) AS rn
FROM Activity
)
SELECT player_id, event_date AS first_login
FROM Ranked
WHERE rn = 1;
이 방법은 각 player_id별 가장 빠른 event_date에 대해 rn = 1인 행만 선택하는 방식입니다.
즉, GROUP BY 없이도 문제를 해결할 수 있지만, 성능적인 차이가 있을 수 있습니다.
두 풀이의 차이는?
두 접근법은 같은 결과를 내지만, 내부적인 동작 방식과 성능에서 차이가 있습니다.
GROUP BY + MIN()을 이용한 쿼리의 장점
1. 단순하고 직관적
2. MIN() 연산이 그룹 내에서 한 번만 수행되므로 성능면에서 더 빠름
3. 인덱스 최적화 가능 (event_date에 인덱스가 있다면 인덱스 스캔 활용 가능)
GROUP BY + MIN()을 이용한 쿼리의 단점
첫 로그인 날짜 외 추가 정보(device_id)를 가져오기가 어려움
예를 들어, "첫 로그인 날짜의 device_id도 함께 조회"하려면 JOIN 필요
ROW_NUMBER() OVER() 이용한 풀이의 장점
첫 로그인 시점의 다른 컬럼(device_id, games_played 등)도 쉽게 가져올 수 있음
→ SELECT player_id, event_date, device_id WHERE rn = 1
중복 데이터 처리에 유용 (같은 event_date가 여러 개일 경우 ORDER BY를 추가하여 정렬 기준을 명확히 설정 가능)
ROW_NUMBER() OVER() 이용한 쿼리의 단점
연산이 조금 더 복잡함 (ORDER BY 포함 시, 데이터셋이 클 경우 성능 저하 가능)
인덱스 최적화가 어렵다 (PARTITION BY와 ORDER BY를 함께 사용하면 인덱스 활용이 제한될 수 있음)
결론
데이터가 매우 크고, 추가적인 정보가 필요 없다면?
👉 GROUP BY + MIN()이 더 효율적
첫 로그인과 함께 다른 컬럼도 가져와야 한다면?
👉 ROW_NUMBER()가 더 적합
간단한 문제였지만, 풀이 방식의 차이를 비교하여 공부하니,
기존 SQLD를 준비했을 때보다 머리에 더 잘 들어오는 느낌을 받습니다. ㅎㅎ (앞으로도 쭉 이럴 수 있길)
'Tools & Skills > SQL' 카테고리의 다른 글
| 신규 가입자의 2주차 재방문율 감소 문제 (4) | 2025.07.22 |
|---|---|
| [SQL] 프로그래머스 Lv.4 보호소에서 중성화한 동물 (0) | 2025.04.05 |
| 정규화 (0) | 2025.03.19 |
| 서브쿼리(Subquery) (0) | 2025.03.05 |
| RDBMS (1) | 2025.02.06 |